最近打算学习django这门web框架,先收集点教程,之后慢慢总结.
python版本:3.6.3
官方文档:https://docs.python.org/3.6/library/index.html
中文文档:http://www.pythondoc.com/pythontutorial3/index.html
django版本:2.2.7
官方文档:https://docs.djangoproject.com/en/2.2/
中文文档:django2.2基础教程
问题汇总(此部分和正文无关,略过)
requests模块使用
https://www.cnblogs.com/lanyinhao/p/9634742.html
数据库的增删改查
https://www.cnblogs.com/py-web/archive/2019/05/22/10907206.html
环境搭建
安装:
pip install Django**2.2.7(需要先安装python)检查django是否安装成功:
1
2
3
4
5
6import django
django.VERSION
(2, 2, 7, 'final', 0)
django.get_version()
'2.2.7'搭建多个互不干扰的开发环境
这里使用virtualenvwrapper ;其他请看:Python创建虚拟环境
Linux/MacOS: `(sudo) pip install virtualenv virtualenvwrapper`
修改~/.bash_profile或其它环境变量相关文件(如 .bashrc 或用 ZSH 之后的 .zshrc),添加以下语句
1
2
3
export WORKON_HOME=$HOME/.virtualenvs
export PROJECT_HOME=$HOME/workspace
source /usr/local/bin/virtualenvwrapper.sh
修改后使之立即生效(也可以重启终端使之生效):`source ~/.bash_profile`
如果 source ~/.bashrc 后系统报错提示:
bash: /usr/local/bin/virtualenvwrapper.sh: 没有那个文件或目录
修改 source /usr/local/bin/virtualenvwrapper.sh为source ~/.local/bin/virtualenvwrapper.sh
题外话:pycharm导入该虚拟环境运行项目
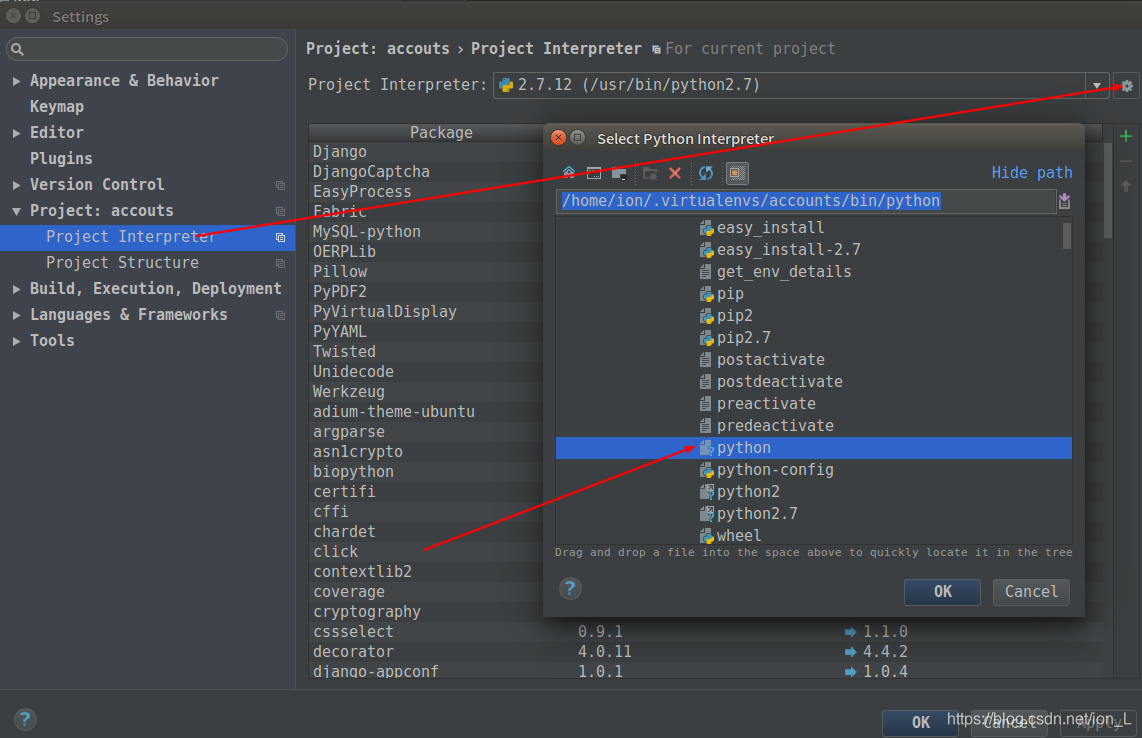
Window: `pip install virtualenv virtualenvwrapper-win`
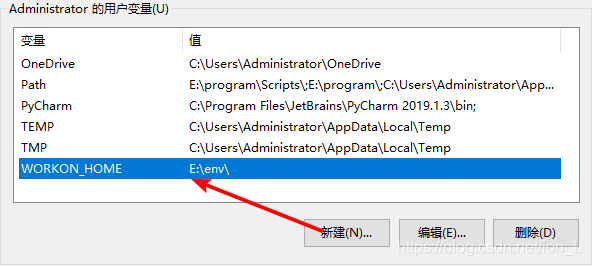
【可选】Windows下默认虚拟环境是放在用户名下面的Envs中的,与桌面,我的文档,下载等文件夹在一块的。更改方法:计算机,属性,高级系统设置,环境
变量,添加WORKON_HOME,如图(windows 10 环境变量设置截图):
虚拟环境使用方法:
mkvirtualenv test:创建运行环境test
workon test: 工作在 test环境 或 从其它环境切换到 test环境
deactivate: 退出终端环境
rmvirtualenv test:删除运行环境test
mkproject test:创建test项目和运行环境test
mktmpenv:创建临时运行环境
lsvirtualenv: 列出可用的运行环境
lssitepackages: 列出当前环境安装了的包
虚拟环境默认位置:C:\Users\Administrator\Envs
创建运行环境时可以通过
-p设置python的版本mkvirtualenv -p /usr/bin/python3.7(python的路径) env37(虚拟环境名)
基础命令
尝试下面命令前可以用虚拟环境去执行。
1 | > workon virtualenv_name |
新建一个 django project
django-admin.py startproject project_name
project_name是项目名,django-admin.py可以改成django-admin
新建 app
cd project_name
python manage.py startapp app_name或 django-admin.py startapp app_name
一般一个项目有多个app, 当然通用的app也可以在多个项目中使用。
使用多个settings模块
https://cloud.tencent.com/developer/article/1370014
settings配置安全问题:https://blog.csdn.net/weixin_39569389/article/details/111459198
创建数据库表 或 更改数据库表或字段
1 | # 1. 创建更改的文件 |
这种方法可以在SQL等数据库中创建与models.py代码对应的表,不需要自己手动执行SQL。
使用开发服务器
开发服务器,即开发时使用,一般修改代码后会自动重启,方便调试和开发,但是由于性能问题,建议只用来测试,不要用在生产环境。
1 | python manage.py runserver |
清空数据库
python manage.py flush
此命令会询问是 yes 还是 no, 选择 yes 会把数据全部清空掉,只留下空表。
上面我们通常不会这么做,对于表结构有更改的情况下,上面的操作并不能使得通过mysqldump备份的数据库应用到本地的项目中。有两种解决方案:
- 首先删除本地数据库,创建数据库,mysql导入数据到新建的数据库中。执行
python manage.py makemigrations,python manage.py migrate - 使用django-extensions插件的命令。首先安装插件django-extensions, 然后执行命令
python manage.py reset_db --noinput(重置数据库 (目前支持 sqlite3, mysql, postgres),可以用来删除或创建数据库.)。其他就和mysql导入数据到新建的数据库中一样了,好处仅仅是不需要重新建立数据库。1
2
3
4
5python manage.py reset_db --noinput
mysql -hlocalhost -uroot -p --database=local_db < db.sql
ls app/migrations/|grep -v __init__.py |xargs rm -rf
python manage.py makemigrations
python manage.py migrate
超级管理员操作
1 | #创建(需要先建立好数据库) |
修改、查、看删除可以通过python shell 轻松实现
1 | ~/projects/test$ python manage.py shell |
导出、导入数据
1 | python manage.py dumpdata appname > appname.json |
Django 项目环境终端
python manage.py shell
如果你安装了 bpython 或 ipython 会自动用它们的界面,推荐安装 bpython。
这个命令和 直接运行 python 或 bpython 进入 shell 的区别是:你可以在这个 shell 里面调用当前项目的 models.py 中的 API,对于操作数据,还有一些小测试非常方便。
数据库命令行
python manage.py dbshell
Django 会自动进入在settings.py中设置的数据库,如果是 MySQL 或 postgreSQL,会要求输入数据库用户密码。在这个终端可以执行数据库的SQL语句。如果您对SQL比较熟悉,可能喜欢这种方式。
10. 更多命令
终端上输入 python manage.py 可以看到详细的列表,在忘记子名称的时候特别有用。
视图与网址
- 首先,新建一个项目(project), 名称为 mysite
django-admin startproject mysite
运行后,如果成功的话, 我们会看到如下的目录样式 (没有成功的请参见环境搭建一节):1
2
3
4
5
6
7mysite
├── manage.py
└── mysite
├── __init__.py # python包的目录结构必须的,与调用有关
├── settings.py # 项目的设置
├── urls.py # 总的urls配置文件
└── wsgi.py # 部署服务器时用到 - 新建一个应用(app), 名称叫 learn
python3 manage.py startapp learn # learn是一个app的名称
目录结构1
2
3
4
5
6
7
8
9learn
├── __init__.py
├── admin.py 后台相关的设置
├── apps.py app相关的设置文件
├── migrations 数据库变更相关
│ └── __init__.py
├── models.py 数据库模型相关
├── tests.py 单元测试
└── views.py 视图逻辑 - 把我们新定义的app加到settings.py中的INSTALL_APPS中
修改 mysite/mysite/settings.py1
2
3
4
5
6
7
8
9
10INSTALLED_APPS = [
'django.contrib.admin', # The admin site. You’ll use it shortly.
'django.contrib.auth', # An authentication system.
'django.contrib.contenttypes', # A framework for content types.
'django.contrib.sessions', # A session framework.
'django.contrib.messages', # A messaging framework.
'django.contrib.staticfiles', # A framework for managing static files.
'learn', # 注意添加了这一行
]这一步是干什么呢? 新建的 app 如果不加到 INSTALL_APPS 中的话, django 就不能自动找到app中的模板文件(app-name/templates/下的文件)和静态文件(app-name/static/中的文件)
- 定义视图函数(访问页面时的内容)
我们在app这个目录中,把views.py打开,修改其中的源代码,改成下面的1
2
3
4
5
6from django.http import HttpResponse
def index(request):
name = request.GET.get('name', 'ion')
content = "欢迎光临 " + name + "!"
return HttpResponse(content) - 定义视图函数相关的URL(网址)
打开 mysite/mysite/urls.py 这个文件, 修改其中的代码:1
2
3
4
5
6
7
8from django.contrib import admin
from django.urls import path
from learn import views as app_views # index
urlpatterns = [
path("", app_views.index), # index
path('admin/', admin.site.urls),
] - 在终端上运行
python manage.py runserver, 点击打开。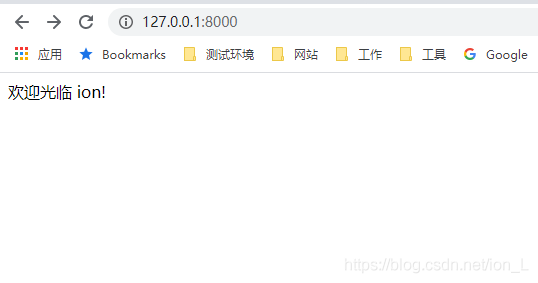
URL name详解
- 打开 mysite > mysite > url.py
1
2
3
4
5
6
7
8
9
10from django.contrib import admin
from django.urls import path
from learn import views as learn_views
urlpatterns = [
path("", learn_views.index, name='homepage'),
path('add/', learn_views.add, name='add'),
path('add/<int:a>/<int:b>/', learn_views.add2, name='add2'),
path('admin/', admin.site.urls),
] - 编辑 mysite > learn > views.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from django.shortcuts import render
from django.http import HttpResponse
def index(request):
return render(request, 'homepage.html')
def add(request):
a = request.GET['a']
b = request.GET['b']
c = int(a) + int(b)
return HttpResponse(str(c))
def add2(request, a, b):
c = int(a) + int(b)
return HttpResponse(str(c)) - 在mysite > learn > templates下建立首页模板 homepage.html
默认配置下,Django 的模板系统会自动找到app下面的templates文件夹中的模板文件。好了,接下来进入正题。url(r’^add/$’, calc_views.add, name=’add’), 这里的 name=’add’ 是用来干什么的呢?1
2
3
4
5
6
7
8
9
10
11
12
13
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<a href="/add/4/5">计算 4+5</a>
</body>
</html>
简单说,name 可以用于在templates, models, views ……中得到对应的网址,相当于“给网址取了个名字”,只要这个名字不变,网址变了也能通过名字获取到。
templates中根据url别名获取对应网址:
1 | <!-- |
models, views中根据url别名获取对应网址:
1 | # reverse() 接收 url 中的 name 作为第一个参数 |
用户收藏夹中收藏的URL是旧的,如何让以前的 /add?a=3&b=4自动跳转到现在新的网址呢?
要知道Django不会帮你做这个,这个需要自己来写一个跳转方法:
1 | from django.http import HttpResponseRedirect |
这里修改了原来的 add/?a=3&b=4 这个链接定向到新的链接 add/3/4
Django模板
网站模板的设计,一般的,我们做网站有一些通用的部分,比如 导航,底部,广告等等。
可以写一个 base.html 来包含这些通用文件(include)
1 |
|
如果需要,写足够多的 block 以便继承的模板可以重写该部分,include 是包含其它文件的内容,就是把一些网页共用的部分拿出来,重复利用,改动的时候也方便一些.
比如我们的首页 homepage.html,就可以继承或者说扩展(extends)原来的 base.html,可以简单这样写,重写部分代码
1 | {% extends 'base.html' %} |
注意:
模板一般放在app下的templates中,Django会自动去这个文件夹中找。但 假如我们每个app的templates中都有一个 index.html,当我们在views.py中使用的时候,直接写一个 render(request, ‘index.html’),Django 能不能找到当前 app 的 templates 文件夹中的 index.html 文件夹呢?(答案是不一定能,有可能找错)
Django 模板查找机制: Django 查找模板的过程是在每个 app 的 templates 文件夹中找(而不只是当前 app 中的代码只在当前的 app 的 templates 文件夹中找)。各个 app 的 templates 形成一个文件夹列表,Django 遍历这个列表,一个个文件夹进行查找,当在某一个文件夹找到的时候就停止,所有的都遍历完了还找不到指定的模板的时候就是 Template Not Found (过程类似于Python找包)。这样设计有利当然也有弊,有利是的地方是一个app可以用另一个app的模板文件,弊是有可能会找错了。所以我们使用的时候在 templates 中建立一个 app 同名的文件夹,这样就好了。这样,使用的时候,模板就是 "app1/index.html" 和 "app2/index.html" 这样有app作为名称的一部分,就不会混淆。
Django模板进阶
主要内容:
- 列表,字典,类的实例的使用
- 循环:迭代显示列表,字典等中的内容
- 条件判断:判断是否显示该内容,比如判断是手机访问,还是电脑访问,给出不一样的代码。
- 标签:for,if 这样的功能都是标签。
- 过滤器:管道符号后面的功能,比如{{ var|length }},求变量长度的 length 就是一个过滤器。
实例一,显示字符串,列表,字典的内容
views.py
1 | # -*- coding: utf-8 -*- |
homepage.html
1 | {% extends 'base.html' %} |
结果如下:
实例二,for 循环的详细操作
在for循环中还有很多有用的东西,如下:
| 变量 | 描述 |
|---|---|
| forloop.counter | 索引从 1 开始算 |
| forloop.counter0 | 索引从 0 开始算 |
| forloop.revcounter | 索引从最大长度到 1 |
| forloop.revcounter0 | 索引从最大长度到 0 |
| forloop.first | 当遍历的元素为第一项时为真 |
| forloop.last | 当遍历的元素为最后一项时为真 |
| forloop.parentloop | 用在嵌套的 for 循环中,获取上一层 for 循环的 forloop |
当列表中可能为空值时用 for……empty
1 | <ul> |
实例三,条件判断
1 | {% for item in list %} |
实例四,逻辑操作
**, !=, >=, <=, >, < 这些比较都可以在模板中使用and, or, not, in, not in 也可以在模板中使用
1 | {% if num <= 100 and num >= 0 %} |
实例五,模板中 获取当前网址,当前用户等
在 views.py 中用的 render 函数,而不是 render_to_response,这样在 模板中我们就可以获取到 request 变量。
- 获取当前用户:
{{ request.user }}
举个栗子,如果登陆就显示内容,不登陆就不显示内容:1
2
3
4
5{% if request.user.is_authenticated %}
{{ request.user.username }},您好!
{% else %}
请登陆,这里放登陆链接
{% endif %} - 获取当前网址:
{{ request.path }} - 获取当前 GET 参数:
{{ request.GET.urlencode }}
举个栗子,url是 http://127.0.0.1:8010/?a=1&b=2,拿到结果为:a=1&b=2
实例六,模板中定义变量
1 | {% with x=1+2 y=x+1 %} |
如上,变量在with
内置过滤器大全
1、add :将value的值增加2。使用形式为:{{ value | add: “2”}}。
2、addslashes:在value中的引号前增加反斜线。使用形式为:{{ value | addslashes }}。
3、capfirst:value的第一个字符转化成大写形式。使用形式为:{{ value | capfirst }}。
4、cut:从给定value中删除所有arg的值。使用形式为:{{ value | cut:arg}}。
5、date: 格式化时间格式。使用形式为:{{ value | date:”Y-m-d H:M:S” }}
6、default:如果value是False,那么输出使用缺省值。使用形式:{{ value | default: “nothing” }}。例如,如果value是“”,那么输出将是nothing
7、default_if_none:如果value是None,那么输出将使用缺省值。使用形式:{{ value | default_if_none:”nothing” }},例如,如果value是None,那么输出将是nothing
8、dictsort:如果value的值是一个字典,那么返回值是按照关键字排序的结果
使用形式:{{ value | dictsort:”name”}},例如,
如果value是:
[{‘name’: ‘python’},{‘name’: ‘java’},{‘name’: ‘c++’},]
那么,输出是:
[{‘name’: ‘c++’},{‘name’: ‘java’},{‘name’: ‘python’}, ]
9、dictsortreversed:如果value的值是一个字典,那么返回值是按照关键字排序的结果的反序。使用形式:与dictsort过滤器相同。
10、divisibleby:如果value能够被arg整除,那么返回值将是True。使用形式:{{ value | divisibleby:arg}},如果value是9,arg是3,那么输出将是True
11、escape:替换value中的某些字符,以适应HTML格式。使用形式:{{ value | escape}}。例如,< 转化为 <> 转化为 >’ 转化为 '” 转化为 "
13、filesizeformat:格式化value,使其成为易读的文件大小。使用形式:{{ value | filesizeformat }}。例如:13KB,4.1MB等。
14、first:返回列表/字符串中的第一个元素。使用形式:{{ value | first }}
16、iriencode:如果value中有非ASCII字符,那么将其进行转化成URL中适合的编码,如果value已经进行过URLENCODE,改操作就不会再起作用。使用形式:{{value | iriencode}}
17、join:使用指定的字符串连接一个list,作用如同python的str.join(list)。使用形式:{{ value | join:”arg”}},如果value是[‘a’,’b’,’c’],arg是’//‘那么输出是a//b//c
18、last:返回列表/字符串中的最后一个元素。使用形式:{{ value | last }}
19、length:返回value的长度。使用形式:{{ value | length }}
20、length_is:如果value的长度等于arg的时候返回True。使用形式:{{ value | length_is:”arg”}}。例如:如果value是[‘a’,’b’,’c’],arg是3,那么返回True
21、linebreaks:value中的”\n”将被
替代,并且整个value使用
22、linebreaksbr:value中的”\n”将被
替代。使用形式:{{value |linebreaksbr}}
23、linenumbers:显示的文本,带有行数。使用形式:{{value | linenumbers}}
24、ljust:在一个给定宽度的字段中,左对齐显示value。使用形式:{{value | ljust}}
25、center:在一个给定宽度的字段中,中心对齐显示value。使用形式:{{value | center}}
26、rjust::在一个给定宽度的字段中,右对齐显示value。使用形式:{{value | rjust}}
27、lower:将一个字符串转换成小写形式。使用形式:{{value | lower}}
30、random:从给定的list中返回一个任意的Item。使用形式:{{value | random}}
31、removetags:删除value中tag1,tag2….的标签。使用形式:{{value | removetags:”tag1 tag2 tag3…”}}
32、safe:当系统设置autoescaping打开的时候,该过滤器使得输出不进行escape转换。使用形式:{{value | safe}}
33、safeseq:与safe基本相同,但有一点不同的就是:safe是针对字符串,而safeseq是针对多个字符串组成的sequence
34、slice:与python语法中的slice相同。使用形式:{{some_list | slice:”2”}}
37、striptags:删除value中的所有HTML标签.使用形式:{{value | striptags}}
38、time:格式化时间输出。使用形式:{{value | time:”H:i”}}或者{{value | time}}
39、title:转换一个字符串成为title格式。
40、truncatewords:将value切成truncatewords指定的单词数目。使用形式:{{value | truncatewords:2}}。例如,如果value是Joel is a slug 那么输出将是:Joel is …
42、upper:转换一个字符串为大写形式
43、urlencode:将一个字符串进行URLEncode
46、wordcount:返回字符串中单词的数目
Django模型(数据库)
Django 模型是与数据库相关的,与数据库相关的代码一般写在 models.py 中,Django 支持 sqlite3, MySQL, PostgreSQL等数据库,只需要在settings.py中配置即可,不用更改models.py中的代码,丰富的API极大的方便了使用。
另外,django中默认安装的数据库是sqlite3, 在 setting.py 文件可以看到: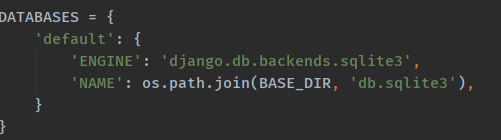
下面就让我们来建立一个用户信息表吧!
1. 打开 learn/models.py 文件,修改其中的代码如下:
1 | from django.db import models |
注意: 这里就使用到了五种Field,其他可以参考:https://docs.djangoproject.com/en/2.2/topics/db/models/
2. 创建数据表我们使用默认的数据库 SQLite3,无需配置
第一步,生成迁移文件
先 cd 进入 manage.py 所在的那个文件夹下,输入下面的命令: python manage.py makemigrations
需要记住,这时候,数据库还没真正变化,只是生成了描述数据库变化的文件,生成的文件在 migrations 目录下。
将结构变化应用到数据库python manage.py migrate
效果如下图,这里只有一个 migrate 记录是因为我之前执行过了,如果没有的话还有很多 django 内置的应用的表,他们是用户及用户认证等相关的。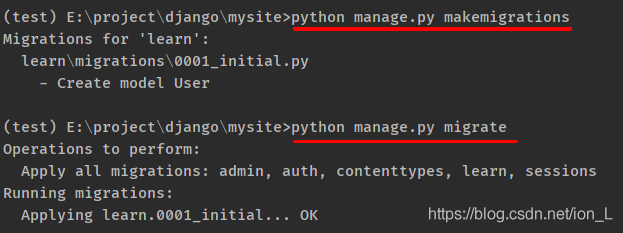
3. 添加和查询数据
1 | from learn.models import User |
新建一个对象的方法有以下几种:
User.objects.create(name='ion',age=23)p = User(name="ion", age=23)
p.save()p = User()
p.name="ion"
p.age = 23
p.save()User.objects.get_or_create(name="ion", age=23)
这种方法是防止重复很好的方法,但是速度要相对慢些,返回一个元组,第一个为User对象,第二个为True或False, 新建时返回的是True, 已经存在时返回False.
获取对象有以下方法:
User.objects.all()
User.objects.all()[:10]
切片操作,不支持负索引`User.objects.all().first()`User.objects.get(name='ion')
get是用来获取一个对象的,如果需要获取满足条件的一些人,就要用到filterUser.objects.filter(name="ion")# 名字严格等于 “ion” 的人
扩展User.objects.filter(name__exact="ion") # 名字严格等于 “ion” 的人User.objects.filter(name__iexact="ion") # 名称为 ion 但是不区分大小写User.objects.filter(name__contains="ion") # 名称中包含 “ion”的人User.objects.filter(name__icontains="ion") #名称中包含 “ion”,且ion不区分大小写User.objects.filter(name__regex="^ion") # 正则表达式查询User.objects.filter(name__iregex="^ion") # 正则表达式不区分大小写
filter是找出满足条件的,当然也有排除符合某条件的User.objects.exclude(name__contains="ion") # 排除包含 ion的User对象User.objects.filter(name__contains="ion").exclude(age=23) # 找出名称含有ion, 但是排除年龄是23岁的
更多可参考:https://blog.csdn.net/qq_43629857/article/details/111239652
Django QuerySet API
从数据库中查询出来的结果一般是一个集合,这个集合叫做 QuerySet。
1.QuerySet 创建对象的方法
1 | from learn.models import User |
备注: 前三种方法返回的都是对应的 object,最后一种方法返回的是一个元组,(object, True/False),创建时返回 True, 已经存在时返回 False
当有一对多,多对一,或者多对多的关系的时候,先把相关的对象查询出来(这个例子没有写出model,知道blog是个外键就好了)
1 | from blog.models import Entry |
2. 获取对象的方法
1 | User.objects.all() # 查询所有 |
3. 删除符合条件的结果(危险操作,正式场合操作务必谨慎)
1 | User.objects.filter(name__contains="abc").delete() # 删除 名称中包含 "abc"的人 |
4. 更新某个内容(危险操作,正式场合操作务必谨慎)
(1) 批量更新,适用于 .all() .filter() .exclude() 等后面
1 | User.objects.filter(name__contains="abc").update(name='xxx') # 名称中包含 "abc"的人 都改成 xxx |
(2) 单个 object 更新,适合于 .get(), get_or_create(), update_or_create() 等得到的 obj,和新建很类似。
1 | ion = User.objects.get(name="ion") |
(3) 复杂的批量更新,适用于Queryset ( 该方式效率不高 )
1 | import re |
5. QuerySet 是可迭代的
1 | user = User.objects.all() |
注意事项:
(1). 如果只是检查 User中是否有对象,应该用 User.objects.all().exists()
(2). QuerySet 支持正索引切片 User.objects.all()[:10] 取出10条,可以节省内存
(3). 用 len(user) 可以得到User的数量,但是推荐用 User.objects.count() 来查询数量,后者用的是SQL:SELECT COUNT(*)
(4). list(user) 可以强行将 QuerySet 变成 列表
6. QuerySet 是可以用pickle序列化到硬盘再读取出来的
1 | import pickle |
7. QuerySet 查询结果排序
1 | User.objects.all().order_by('created_on') # 按照创建时间排序 |
8. QuerySet 支持链式查询
1 | User.objects.filter(name__contains="ion").filter(email="ionluo@163.com") |
9. QuerySet 不支持负索引
1 | User.objects.all()[:10] # 切片操作,前10条 |
10. QuerySet 重复的问题,使用 .distinct() 去重
一般的情况下,QuerySet 中不会出来重复的,重复是很罕见的,但是当跨越多张表进行检索后,结果并到一起,可能会出来重复的值(我最近就遇到过这样的问题)
1 | qs1 = Test.objects.filter(label__name='x') |
Django QuerySet API进阶
用到再总结
Django 自定义Field
举例:
减少文本的长度,保存数据的时候压缩,读取的时候解压缩,如果发现压缩后更长,就用原文本直接存储:
使用可以参考:https://code.ziqiangxuetang.com/django/django-custom-field.html
1 | # django1.8 以上版本,可以用 |
Django 数据表更改
我们设计数据库的时候,早期设计完后,后期会发现不完善,要对数据表进行更改,这时候就要用到本节的知识。
Django 1.7.x 和后来的版本:
Django 1.7.x 及以后的版本集成了 South 的功能,在修改models.py了后运行:python manage.py makemigrationspython manage.py migrate
这两行命令就会对我们的models.py 进行检测,自动发现需要更改的,应用到数据库中去。
Django 后台
- 在 learn 文件夹中的 models.py 增加 Article 类
1
2
3
4
5
6
7
8
9
10
11class Article(models.Model):
title = models.CharField(u'标题', max_length=256)
content = models.TextField(u'内容')
status = models.CharField(u'状态', max_length=25, default='未发布')
comment = models.TextField(u'备注', default='')
pub_date = models.DateTimeField(u'发表时间', auto_now_add=True, editable=True)
update_time = models.DateTimeField(u'更新时间', auto_now=True, null=True)
def __str__(self): # 在Python2中用 __unicode__ 代替 __str__
return self.title - 同步所有的数据表
1
2
3# 进入包含有 manage.py 的文件夹
python manage.py makemigrations
python manage.py migrate - 创建超级管理员
python manage.py createsuperuser - 修改 learn > admin.py文件(如果没有新建一个)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from django.contrib import admin
from .models import Article
class ArticleAdmin(admin.ModelAdmin):
list_display = ('title', 'pub_date', 'update_time',) # 列表展示thead
search_fields = ('title', 'content',) # 搜索功能
list_filter = ('pub_date',) # 筛选功能
fieldsets = (
('Base Info', {
'fields': ('title', 'content',)
}),
('Other Info', {
'classes': ('collapse',),
'fields': ('comment', 'status'),
}),
), # 布局
admin.site.register(Article, ArticleAdmin) - 用创建的超级管理员登录后台
域名 + /admin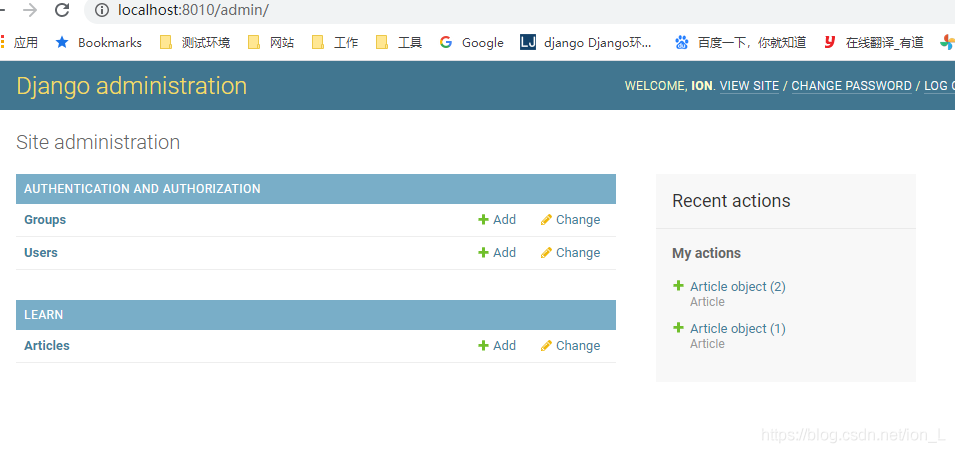
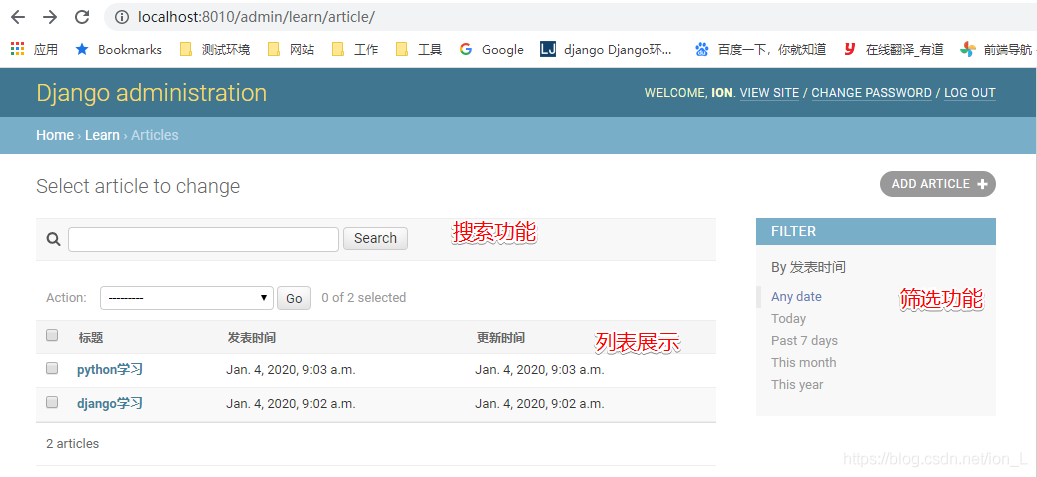
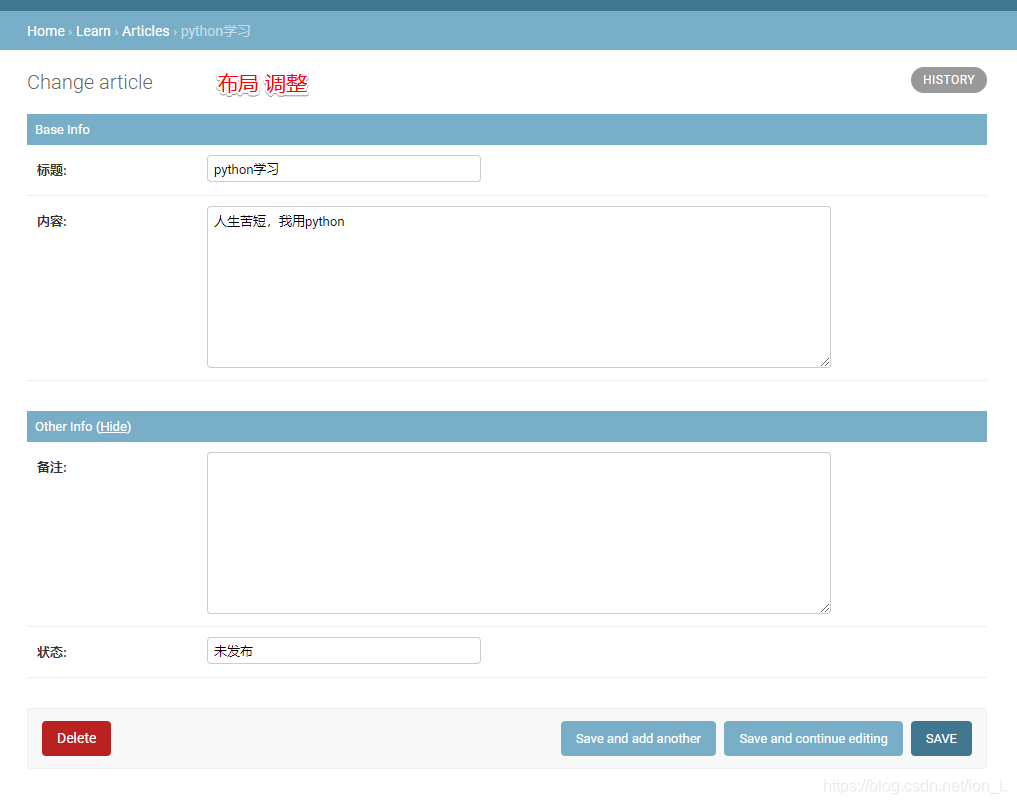
扩展:
搜索功能:https://docs.djangoproject.com/en/dev/ref/contrib/admin/#django.contrib.admin.ModelAdmin.search_fields
筛选功能:
https://docs.djangoproject.com/en/dev/ref/contrib/admin/#django.contrib.admin.ModelAdmin.list_filter
新增或修改时的布局顺序:https://docs.djangoproject.com/en/dev/ref/contrib/admin/#django.contrib.admin.ModelAdmin.fieldsets
Django 表单
在 learn 文件夹中新建一个 forms.py 文件
1 | from django import forms |
我们的视图函数 views.py 中
1 | # coding:utf-8 |
对应的模板文件 index.html
1 | <form method='post'> |
再在 urls.py 中对应写上这个函数
1 | from django.contrib import admin |
效果: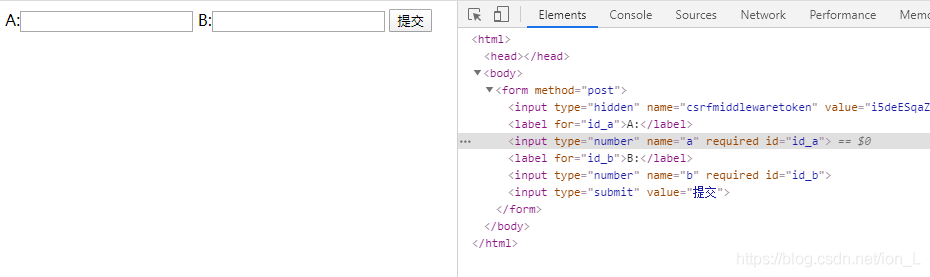
新手可能觉得这样变得更麻烦了,有些情况是这样的,但是 Django 的 forms 提供了:
- 模板中表单的渲染
- 数据的验证工作,某一些输入不合法也不会丢失已经输入的数据。
- 还可以定制更复杂的验证工作,如果提供了10个输入框,必须必须要输入其中两个以上,在 forms.py 中都很容易实现
Django关系
反查:
在表关系里 related_name = ‘反查name’,自己不设置,django也会默认设置为class的小写名字+_set , example: book_set.
一对一关系赋值:
1 | class ModelStudy(View): |
多对一:
类似一对一,只是 ‘’多’’的一方可以对应多个”一”方。 ps: “一”放通过反查,会有不止一条数据。可以通过+all()获取。
假设两张表:Book书 + Reply评论 表。为多对一,Reply为”多’’. 那么”一”,Book反查是,Book.object.get(id=1).reply_set.all() # reply_set是不设置related_name时,django自己设置的
多对多:
1 | class ModelStudy(View): |
删除关系数据
先查出对应的关系数据,再删除:
1 | class ModelStudy(View): |
Django 配置
os
运行 django-admin.py startproject [project-name] 命令会生成一系列文件,在Django 2.2.7版本的 settings.py 文件中有以下语句:
1 | import os |
__file__ 这个变量可以获取到当前文件(包含这个代码的文件)的路径;os.path.dirname() 得到文件所在目录;os.path.dirname(os.path.dirname(__file__)) 得到的就是目录的上一级;os.path.abspath() 返回绝对路径BASE_DIR 即为 项目 所在目录。我们在后面的与目录有关的变量都用它,这样使得移植性更强。
举个栗子:
1 | import os |
DEBUG=True
开启debug模式(调试模式),如果出现 bug 便于我们看见问题所在,但是部署时最好不要让用户看见bug的详情,可能一些不怀好心的人攻击网站,造成不必要的麻烦。
ALLOWED_HOSTS = ['*.besttome.com','www.ziqiangxuetang.com']
ALLOWED_HOSTS 允许你设置哪些域名可以访问,即使在 Apache 或 Nginx 等中绑定了,这里不允许的话,也是不能访问的。
当 DEBUG=False 时,这个为必填项,如果不想输入,可以用 ALLOW_HOSTS = [‘*’] 来允许所有的。
设置静态文件位置
设置静态文件目录
1 | STATIC_URL = '/static/' |
static 是静态文件所有目录,比如 jquery.js, bootstrap.min.css 等文件。
一般来说我们只要把静态文件放在 APP 中的 static 目录下,部署时用 python manage.py collectstatic 就可以把静态文件收集到(复制到) STATIC_ROOT 目录,但是有时我们有一些共用的静态文件,这时候可以设置 STATICFILES_DIRS 另外弄一个文件夹,如下:
1 | STATICFILES_DIRS = ( |
这样我们就可以把静态文件放在 common_static 和 /var/www/static/中了,Django也能找到它们。
设置用户上传的文件目录
1 | MEDIA_URL = '/media/' |
media文件夹用来存放用户上传的文件.
设置模板文件目录
有时候有一些模板不是属于app的,比如 baidutongji.html, share.html等,
Django 1.5 - Django 1.7
1 | TEMPLATE_DIRS = ( |
Django 1.8 及以上版本
1 | TEMPLATES = [ |
这样 就可以把模板文件放在 templates 和 templates2 文件夹中了。
部署基础
本文主要讲在 Linux 平台下,使用 Nginx + uWSGI 的方式来部署来 Django,这是目前比较主流的方式。当然你也可以使用 Gunicorn 代替 uWSGI,不过原理都是类似的。
基础知识储备
当我们发现用浏览器不能访问的时候,我们需要一步步排查问题。
整个部署的链路是 Nginx -> uWSGI -> Python Web程序,通常还会提到supervisord工具。
uWSGI是一个软件,部署服务的工具,了解整个过程,我们先了解一下WSGI规范,uwsgi协议等内容。
WSGI(Web Server Gateway Interface)规范,WSGI规定了Python Web应用和Python Web服务器之间的通讯方式。目前主流的Python Web框架,比如Django,Flask,Tornado等都是基于这个规范实现的。
uwsgi协议是uWSGI工具独有的协议,简洁高效的uwsgi协议是选择uWSGI作为部署工具的重要理由之一,详细的 uwsgi协议 可以参考uWSGI的文档。uWSGI是 实现了uwsgi协议,WSGI规范和HTTP协议的 一个C语言实现的软件。
Nginx是一个Web服务器,是一个反向代理工具,我们通常用它来部署静态文件。主流的Python Web开发框架都遵循WSGI规范。
uWSGI通过WSGI规范和我们编写的服务进程通讯,然后通过自带的高效的 uwsgi 协议和 Nginx进行通讯,最终Nginx通过HTTP协议将服务对外透出。
当一个访问进来的时候,首先到 Nginx,Nginx会把请求(HTTP协议)转换uwsgi协议传递给uWSGI,uWSGI通过WSGI和web server进行通讯取到响应结果,再通过uwsgi协议发给Nginx,最终Nginx以HTTP协议发现响应给用户。
有些同学可能会说,uWSGI不是支持HTTP协议么,也支持静态文件部署,我不用Nginx行不行?
当然可以,这么做没问题,但目前主流的做法是用Nginx,毕竟它久经考验,更稳定,当然也更值得我们信赖。
supervisor 是一个进程管理工具。任何人都不能保证程序不异常退出,不别被人误杀,所以一个典型的工程做法就是使用supervisor看守着你的进程,一旦异常退出它会立马进程重新启动起来。如果服务部署后出现异常,不能访问。我们需要分析每一步有没有问题,这时候就不得不用到Linux中一些命令。
uwsgi.py设置
1 | [uwsgi] |
进程分析
进程是计算机分配资源的最小单位,我们的程序至少是运行在一个进程中。
查看进程信息
ps aux | grep python( 查看系统中运行的 python 进程)
我们可以通过查看 /proc/PID/ 目录的文件信息来得到这个进程的一些信息(Linux中一切皆文件,进程信息也在文件中),比如它是在哪个目录启动的,启动命令是什么等信息。执行命令如下:1
tu@linux /proc/4491 $ sudo ls -ahl
向进程发送信号
kill PID杀死一个进程kill -9 PID强制杀死一个进程
我们可以通过kill -l命令查看到所有的信号
HUP INT QUIT ILL TRAP ABRT BUS FPE KILL USR1 SEGV USR2 PIPE ALRM TERM STKFLT CHLD CONT STOP TSTP TTIN TTOU URG XCPU XFSZ VTALRM PROF WINCH POLL PWR SYS查看进程打开了哪些文件
sudo lsof -p PID查看文件被哪个进程使用
sudo lsof /path/to/file查看进程当前状态
当我们发现一个进程启动了,端口也是正常的,但好像这个进程就是不“干活”。比如我们执行的是数据更新进程,这个进程不更新数据了,但还是在跑着。可能数据源有问题,可能我们写的程序有BUG,也可能是更新时要写入到的数据库出问题了(数据库连接不上了,写数据死锁了)。我们这里主要说下第二种,我们自己的程序如果有BUG,导致工作不正常,我们怎么知道它当前正在干什么呢,这时候就要用到Linux中的调试分析诊断strace,可以使用
sudo strace -p PID这个命令。通过执行后输出的一些信息,推测分析看是哪些出了问题。
端口分析
查看全部端口占用情况 netstat -nltp
Linux中我们可以使用 netstat 工具来进程网络分析,netstat 命令有非常多选项,这里只列出了常用的一部分
1 | -a或--all 显示所有连接中的Socket,默认不显示 LISTEN 相关的。 |
查看具体端口占用情况 sudo lsof -i :80
功能
Python提取html中的文字
1 | from io import StringIO |
其他
django依赖文件requirements.txt生成/安装
依赖文件生成pip freeze > requirements.txt
依赖文件安装pip install -r requirement.txt
忽略失败安装(仅Linux可用):cat requirements.txt | xargs -n 1 pip install
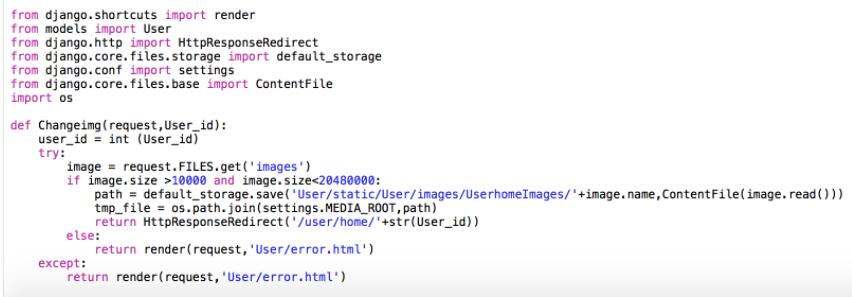
Django后台获取前端post上传的文件方法
1 | from django.core.files.storage import default_storage, FileSystemStorage |
报错处理
Error: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。
·

原因:端口被占用
解决方案:关闭该端口
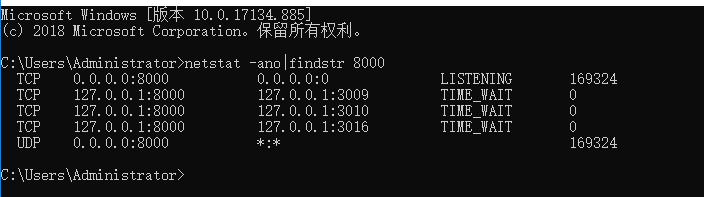
命令:taskkill /pid 进程号 /F用新端口打开
命令:python manage.py runserver 127.0.0.1:新端口号
mkvirtualenv 创建虚拟环境时:Fatal error in launcher: Unable to create process using 系统找不到指定的路径
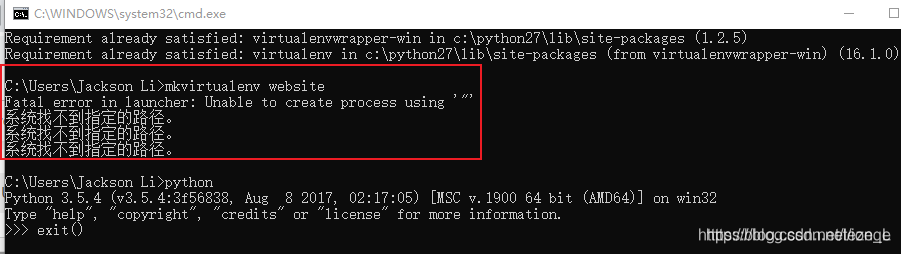
解决方法:更新虚拟环境
python -m pip install upgrade virtualenv
转自:https://blog.csdn.net/lezeqe/article/details/90645663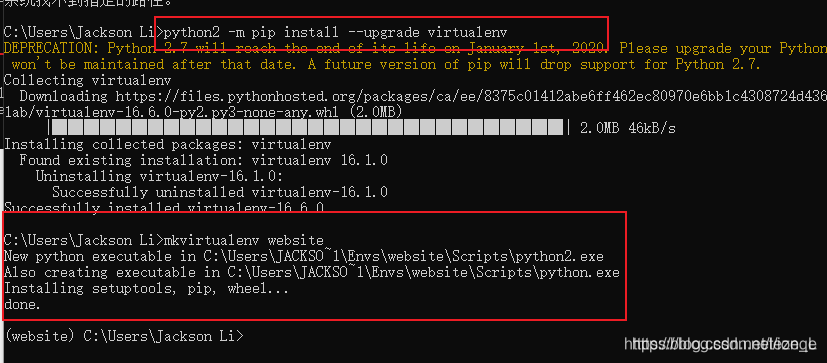
Pip not working - ModuleNotFoundError: No module named ‘runpy’
解决方法:首先检查virtualenv是否正常,然后检查环境变量设置是否正确,最后如果还是有问题删除改虚拟环境重新创建。
原始回答:(转自:https://stackoverflow.com/questions/51405139/pip-not-working-modulenotfounderror-no-module-named-runpy)
Runpy is installed by default with your environment.
If you are using virtualenv, deleting and creating another one should fix the problem.
If you are trying to install globally, try to re-install Python and/or checking the PATH in windows environment variables.本地,测试,正式部署时候migration文件夹内的文件不一致导致makemigrations或者migrate失败。
这里首先建议本地和测试使用相同的数据库,因为本地和测试的数据库都是测试数据库,通常表都是一致,没有必要区分,避免了测试和本地数据库不一致导致的问题。
makemigrations失败:
大多数情况下可以通过python mange.py makemigrations --merge处理(不建议)。
如果上面的方式不行,说明migration的冲突已经比较严重了,django无法自动合并。通常我遇到都是由于出现序号相同并且不是最后的的migrations文件。这时候即使merge了也无法进入下一步的migrate。可以通过修改migrations文件夹中的文件名和文件内容去控制,文件名序号不能重复,文件内容主要就是分为dependencies和operations这两个部分,可以修改,但是不建议这样子做。我是只修改过dependencies。绝大多数的问题就是出现在这里的,只要管理好makemigrations,可以解决django应用数据库的80%问题。因此与其花费大量时间去纠错,不如做好migrations的文件管控,将migrations纳入版本控制。出现问题的时候尽量不要通过merge的方式去处理,一次merge,次次merge。
migrate失败:
如果是失败原因是数据表都已经存在了,在migrate时直接使用--fake-initial来处理python manage.py migrate --fake-initial
如果是因有外键存在,需要初始化多个表,且有部分数据表已创建,又有部分未创建,可以使用--fake <appname>来处理python manage.py migrate --fake <appname>终极:
实在不行,还有一个万不得已的办法。几乎所有的数据库错误都可以用这个方法解决:
将migrations文件夹下的文件除了__init__.py全部删掉,然后将数据库drop掉,重新建数据库。然后python manage.py makemigrations,python manage.py migrate,就可以使用一个新的数据库(但愿你永远用不到这个方法, 因为数据也会随着数据库一起删除)。数据库的命令稍有不慎可能就会掉坑。特别是migrate命令,由于django的数据库中包含了migrations的记录,如果migrations文件丢失,很可能造成migrate失败。所以有必要将migrations文件加入版本控制,保证开发时的migrations记录和文件相匹配。
如果migrate出现了失败,很可能是因为migration文件包含的变更信息由于当前数据库的约束无法完完成。这时就应该去数据中找到这些记录或键的位置,删掉重做即可。
一般这些数据存在的表为:外键约束对应的表、auth_permission、django_content_type和django_migrations.
扩展:
如果想要精确到某个迁移文件(0004_xxx.py):python manage.py migrate app_name 0004
如果想看迁移文件的执行状态:python manage.py showmigrations
直接删除migrations文件夹里面的文件是无法重新python manage.py makemigrations的,因为记录是存储在数据库中的,需要把表记录也删掉,具体可以百度如何操作。
python makemigrations: 在app/migrations文件夹下生成迁移文件
python migrate: 在数据库表django-migrations中记录迁移文件记录,然后应用变化到数据库中。
django 构建Web API的框架


django的库
django官方文档:
https://docs.djangoproject.com/zh-hans/3.0/
django-mptt文档(目录树实现)
http://django-mptt.github.io/django-mptt/index.html
参考
本文链接: http://www.ionluo.cn/blog/posts/79fab809.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
