一次性搞懂JavaScript正则表达式之语法
作者:马蹄疾 奇舞精选
出处:https://mp.weixin.qq.com/s/KE_Bjxk8I1QBUegBOR0mYw
仅做备份学习用,排版未整理,为了更好的阅读体验请查看原文
名余曰正则兮,字余曰灵均。
Regular Expressions翻译成中文叫正则表达式。也不知道是谁翻译过来的,听起来就很严肃。似乎翻译成通用表达式更能传达其精髓,如果你不怕梦见屈原的话。
为什么叫通用表达式?因为它有一套和编程语言无关的文本匹配规则。很多语言都实现了正则表达式的文本匹配引擎,只不过在功能集合上略有不同。
我们要记住的是三点:
其一,正则表达式是用来提取文本的。
其二,正则表达式的表达能力强大到令人发指。
其三,正则表达式的语法对初学者不友好。
另外,本专题只涉及JavaScript语言的正则表达式,其他语言的规则可能略有不同。
我还为各位读者准备了一副宣传语,应该能让你心动(点赞)吧?
学一门前端工具,几年就过时了。学正则表达式,受用一辈子。
普通字符
什么叫普通字符?
当我们写a的时候,我们指的就是a;当我们写爱的时候,我们指的就是爱。
这就是普通字符,它在正则中的含义就是检索它本身。除了正则规定的部分字符外,其余的都是普通字符,包括各种人类语言,包括emoji,只要能够表达为字符串。
开始与结束
^字符的英文是caret,翻译成中文是脱字符。不要问我,又不是我翻译的。它在正则中属于元字符,通常代表的意义是文本的开始。说通常是因为当它在字符组中[^abc]另有含义。
什么叫文本的开始?就是如果它是正则主体的第一个符号,那紧跟着它的字符必须是被匹配文本的第一个字符。
问题来了,如果^不是正则的第一个符号呢?
所以呀,关于它有三点需要注意:
- 作为匹配文本开始元字符的时候必须是正则主体的第一个符号,否则正则无效。
- 它匹配的是一个位置,而不是具体的文本。
- 它在其他规则中有另外的含义。
$字符与^正好相反。它代表文本的结束,并且没有其他含义(其实是有的,但不是在正则主体内)。同样,它必须是正则主体的最后一个符号。
^与$特殊的地方在于它匹配的是一个位置。位置不像字符,它看不见,所以更不容易理解。
转义
我们现在已经知道$匹配文本的结束位置,它是元字符。但是如果我想匹配$本身呢?匹配一个美元符号的需求再常见不过了吧。所以我们得将它贬为庶民。
\反斜杠就是干这个的。
上面的例子有点超纲了,超纲的部分先不管。
你可以认为\也是一个元字符,它跟在另一个元字符后面,就能还原它本来的含义。
如果有两个\呢?那就是转义自身了。如果有三个\呢?我们得分成两段去理解。以此类推。
普通字符前面跟了一个\是什么效果?首先它们是一个整体,然后普通字符转义后还是普通字符。
带反斜杠的元字符
一般来说,普通字符前面带反斜杠还是普通字符,但是有一些普通字符,带反斜杠后反而变成了元字符。
要怪只能怪计算机领域的常用符号太少了。
| 元字符 | 含义 |
|---|---|
| \b | 匹配一个单词边界(boundary) |
| \B | 匹配一个非单词边界 |
| \d | 匹配一个数字字符(digit) |
| \D | 匹配一个非数字字符 |
| \s | 匹配一个空白字符(space) |
| \S | 匹配一个非空白字符 |
| \w | 匹配一个字母或者一个数字或者一个下划线(word) |
| \W | 匹配一个字母、数字和下划线之外的字符 |
你这么聪明,肯定一眼就看出来,大写代表反义。对,就是这么好记。
\b元字符
\b匹配的也是一个位置,而不是一个字符。单词和空格之间的位置,就是所谓单词边界。
所谓单词边界,对中文等其他语言是无效的。
所以\b翻译一下就是^\w|\w$|\W\w|\w\W。
\d元字符
\d匹配一个数字,注意,这里的数字不是指JavaScript中的数字类型,因为文本全是字符串。它指的是代表数字的字符。
\s元字符
\s匹配一个空白字符。
这里需要解释一下什么是空白字符。
空白字符不是空格,它是空格的超集。很多人说它是\f\n\r\t\v的总和,其中\f是换页符,\n是换行符,\r是回车符,\t是水平制表符,\v是垂直制表符。是这样么?
这样说的人,明显是没有做过实验。其实正确的写法是空格\f\n\r\t\v的总和,集合里面包含一个空格,可千万别忽略了。诶,难道空格在正则中的写法就是空一格么,是的,就是这样随意。
这个集合中很多都是不可打印字符,估计只有\n是我们的老朋友。所以,如果不需要区分空格和换行的话,那就大胆的用\s吧。
\w元字符
\w匹配一个字母或者一个数字或者一个下划线。为什么要将它们放一起?想一想JavaScript中的变量规则,包括很多应用的用户名都只能是这三样,所以把它们放一起挺方便的。
不过要注意,字母指的是26个英文字母,其他的不行。
负阴抱阳
如果我们将大写和小写的带反斜杠的元字符组合在一起,就能匹配任何字符。是的,不针对任何人。
方括号的含义我们先按下不表。
道生一
.在正则中的含义仙风道骨,它匹配换行符之外的任意单个字符。
如果文本不存在换行符,那么.和[\b\B]和[\d\D]和[\s\S]和[\w\W]是等价的。
如果文本存在换行符,那么(.|\n)和[\b\B]和[\d\D]和[\s\S]和[\w\W]是等价的。
量词
前面我们一直在强调,一个元字符只匹配一个字符。即便强大如.它也只能匹配一个。
那匹配gooooogle的正则是不是得写成/gooooogle/呢?
正则冷笑,并向你发射一个蔑视。
如果匹配的模式有重复,我们可以声明它重复的次数。
| 量词 | 含义 |
|---|---|
| ? | 重复零次或者一次 |
| + | 重复一次或者多次,也就是至少一次 |
| * | 重复零次或者多次,也就是任意次数 |
| {n} | 重复n次 |
| {n,} | 重复n次或者更多次 |
| {n,m} | 重复n次到m次之间的次数,包含n次和m次 |
有三点需要注意:
?在诸如匹配http协议的时候非常有用,就像这样:/http(s)?/。它在正则中除了是量词还有别的含义,后面会提到。
我们习惯用/.*/来匹配若干对我们没有价值的文本,它的含义是若干除换行符之外的字符。比如我们需要文本两头的格式化信息,中间是什么无所谓,它就派上用场了。不过它的性能可不好。
{n,m}之间不能有空格,空格在正则中是有含义的。
关于量词最令人困惑的是:它重复什么?
它重复紧贴在它前面的某个集合。第一点,必须是紧贴在它前面;第二点,重复一个集合。最常见的集合就是一个字符,当然正则中有一些元字符能够将若干字符变成一个集合,后面会讲到。
如果一个量词紧贴在另一个量词后面会怎样?
贪婪模式与非贪婪模式
前面提到量词不能紧跟在另一个量词后面,马上要👋👋打脸了。
然而,我的脸是这么好打的?
紧跟在?后面的?它不是一个量词,而是一个模式切换符,从贪婪模式切换到非贪婪模式。
贪婪模式在正则中是默认的模式,就是在既定规则之下匹配尽可能多的文本。因为正则中有量词,它的重复次数可能是一个区间,这就有了取舍。
紧跟在量词之后加上?就可以开启非贪婪模式。怎么省事怎么来。
这里的要点是,?必须紧跟着量词,否则的话它自己就变成量词了。
字符组
正则中的普通字符只能匹配它自己。如果我要匹配一个普通字符,但是我不确定它是什么,怎么办?
方括号在正则中表示一个区间,我们称它为字符组。
首先,字符组中的字符集合只是所有的可选项,最终它只能匹配一个字符。
然后,字符组是一个独立的世界,元字符不需要转义。
最后,有两个字符在字符组中有特殊含义。
^在字符组中表示取反,不再是文本开始的位置了。
如果我就要^呢?前面已经讲过了,转义。
-本来是一个普通字符,在字符组中摇身一变成为连字符。
连字符的意思是匹配范围在它的左边字符和右边字符之间。
如果我这样呢?
发现什么了没有?只有两种字符是可以用连字符的:英文字母和数字。而且英文字母可以和数字连起来,英文字母的顺序在后面。这和扑克牌1 2 3 4 5 6 7 8 9 10 J Q K是一个道理。
捕获组与非捕获组
我们已经知道量词是怎么回事了,我们也知道量词只能重复紧贴在它前面的字符。
如果我要重复的是一串字符呢?
这样肯定是不行的。是时候请圆括号出山了。
圆括号的意思是将它其中的字符集合打包成一个整体,然后量词就可以操作这个整体了。这和方括号的效果是完全不一样的。
而且默认的,圆括号的匹配结果是可以捕获的。
正则内捕获
现在我们有一个需求,匹配
这很简单。但如果我要匹配的是任意标签,包括自定义的标签呢?
这时候就要用到正则的捕获特性。正则内捕获使用\数字的形式,分别对应前面的圆括号捕获的内容。这种捕获的引用也叫反向引用。
我们来看一个更复杂的情况:
如果有嵌套的圆括号,那么捕获的引用是先递归的,然后才是下一个顶级捕获。
正则外捕获
没错,RegExp就是构造正则的构造函数。如果有捕获组,它的实例属性$数字会显示对应的引用。
如果有多个正则呢?
RegExp构造函数的引用只显示最后一个正则的捕获。
另外还有一个字符串实例方法也支持正则捕获的引用,它就是replace方法。
实际上它才是最常用的引用捕获的方式。
捕获命名
这是ES2018的新特性。
使用\数字引用捕获必须保证捕获组的顺序不变。现在开发者可以给捕获组命名了,有了名字以后,引用起来更加确定。
在捕获组内部最前面加上?
是不是很简单?
通常情况下,开发者只是想在正则中将某些字符当成一个整体看待。捕获组很棒,但是它做了额外的事情,肯定需要额外的内存占用和计算资源。于是正则又有了非捕获组的概念。
只要在圆括号内最前面加上?:标识,就是告诉正则引擎:我只要这个整体,不需要它的引用,你就别费劲了。从上面的例子也可以看出来,match方法返回的结果有些许不一样。
个人观点:我觉得正则的捕获设计应该反过来,默认不捕获,加上?:标识后才捕获。因为大多数时候开发者是不需要捕获的,但是它又懒得加?:标识,会有些许性能浪费。
分支
有时候开发者需要在正则中使用或者。
|就代表或者。字符组其实也是一个多选结构,但是它们俩有本质区别。字符组最终只能匹配一个字符,而分支匹配的是左边所有的字符或者右边所有的字符。
我们来看一个例子:
因为|是将左右两边一切两半,然后匹配左边或者右边。所以上面的正则显然达不到我们想要的效果。这个时候就需要一个东西来缩小分支的范围。诶,你可能已经想到了:
没错,就是圆括号。
零宽断言
正则中有一些元字符,它不匹配字符,而是匹配一个位置。比如之前提到的^和$。^的意思是说这个位置应该是文本开始的位置。
正则还有一些比较高级的匹配位置的语法,它匹配的是:在这个位置之前或之后应该有什么内容。
零宽(zero-width)是什么意思?指的就是它匹配一个位置,本身没有宽度。
断言(assertion)是什么意思?指的是一种判断,断言之前或之后应该有什么或应该没有什么。
零宽肯定先行断言
所谓的肯定就是判断有什么,而不是判断没有什么。
而先行指的是向前看(lookahead),断言的这个位置是为前面的规则服务的。
语法很简单:圆括号内最左边加上?=标识。
上面匹配的是四个字母,这四个字母要满足以下条件:紧跟着的应该是Script字符串,而且Script字符串应该是单词的结尾部分。
所以,零宽肯定先行断言的意思是:现在有一段正则语法,用这段语法去匹配给定的文本。但是,满足条件的文本不仅要匹配这段语法,紧跟着它的必须是一个位置,这个位置又必须满足一段正则语法。
说的再直白点,我要匹配一段文本,但是这段文本后面必须紧跟着另一段特定的文本。零宽肯定先行断言就是一个界碑,我要满足前面和后面所有的条件,但是我只要前面的文本。
我们来看另一种情况:
上面的例子更加直观,零宽肯定先行断言已经匹配过Script一次了,后面的\w+却还是能匹配Script成功,足以说明它的零宽特性。它为紧贴在它前面的规则服务,并且不影响后面的匹配规则。
零宽肯定后行断言
先行是向前看,那后行就是向后看(lookbehind)咯。
语法是圆括号内最左边加上?<=标识。
一个正则可以有多个断言:
零宽否定先行断言
肯定是判断有什么,否定就是判断没有什么咯。
语法是圆括号内最左边加上?!标识。
零宽否定后行断言
语法是圆括号最左边加上?<!标识。
修饰符
正则表达式除了主体语法,还有若干可选的模式修饰符。
写法就是将修饰符安插在正则主体的尾巴上。比如这样:/abc/gi。
g修饰符
g是global的缩写。默认情况下,正则从左向右匹配,只要匹配到了结果就会收工。g修饰符会开启全局匹配模式,找到所有匹配的结果。
i修饰符
i是ignoreCase的缩写。默认情况下,/z/是无法匹配Z的,所以我们有时候不得不这样写:/[a-zA-Z]/。i修饰符可以全局忽略大小写。
很多时候我们不在乎文本是大写、小写还是大小写混写,这个修饰符还是很有用的。
m修饰符
m是multiline的缩写。这个修饰符有特定起作用的场景:它要和^和$搭配起来使用。默认情况下,^和$匹配的是文本的开始和结束,加上m修饰符,它们的含义就变成了行的开始和结束。
y修饰符
这是ES2015的新特性。
y是sticky的缩写。y修饰符有和g修饰符重合的功能,它们都是全局匹配。所以重点在sticky上,怎么理解这个粘连呢?
g修饰符不挑食,匹配完一个接着匹配下一个,对于文本的位置没有要求。但是y修饰符要求必须从文本的开始实施匹配,因为它会开启全局匹配,匹配到的文本的下一个字符就是下一次文本的开始。这就是所谓的粘连。
有人肯定发现了猫腻:你不是说y修饰符是全局匹配么?看上面的例子,单独一个y修饰符用match方法怎么并不是全局匹配呢?
诶,这里说来就话长了。
长话短说呢,就涉及到y修饰符的本质是什么。它的本质有二:
- 全局匹配(先别着急打我)。
- 从文本的lastIndex位置开始新的匹配。lastIndex是什么?它是正则表达式的一个属性,如果是全局匹配,它用来标注下一次匹配的起始点。这才是粘连的本质所在。
不知道你们发现什么了没有:lastIndex是正则表达式的一个属性。而上面例子中的match方法是作用在字符串上的,都没有lastIndex属性,休怪人家工作不上心。
咱们换成正则方法exec,多次执行,正则的lastIndex在变,匹配的结果也在变。全局匹配无疑了吧。
s修饰符
这是ES2018的新特性。
s不是dotAll的缩写。s修饰符要和.搭配使用,默认情况下,.匹配除了换行符之外的任意单个字符,然而它还没有强大到无所不能的地步,所以正则索性给它开个挂。
s修饰符的作用就是让.可以匹配任意单个字符。
s是singleline的缩写。
u修饰符
这是ES2015的新特性。
u是unicode的缩写。有一些Unicode字符超过一个字节,正则就无法正确的识别它们。u修饰符就是用来处理这些不常见的情况的。
𠮷念jí,与吉同义。
笔者对Unicode认识尚浅,这里不过多展开。
不容易自己琢磨出来的正则表达式用法
作者:打码日记
出处:https://mp.weixin.qq.com/s/XBzfXq9e-uPBHRLAKtxxlg
仅做备份学习用,排版未整理,为了更好的阅读体验请查看原文
简介
现如今,正则表达式几乎是程序员的必备技能了,它入手确实很容易,但如果你不仔细琢磨学习,会长期停留在正则最基本的用法层面上。
因此,本篇文章,我会介绍一些能用正则解决的场景,但这些场景如果全自己琢磨实现的话,需要花一些时间才能完成,或者就完全想不出来,另外也会介绍一些正则表达式的性能问题。
匹配多个单词
比如我想匹配zhangsan、lisi、wangwu这三个人名,这是一个很常见的场景,其实在正则里面也算基本功,但鉴于本人初入门时还是在网上搜索得到的答案,还是值得提一下的!
实现如下:
1 | zhangsan|lisi|wangwu |
其中|表示或的含义,就是匹配zhangsan或lisi或wangwu了。
匹配重复数字
匹配如1111、2222、3333这样的4位长度的重复数字,突一想,这不用\d{4}就解决了嚒,其实不然,因为\d{4}可以匹配1111,但也可以匹配1234啊。
写法如下:
1 | (\d)\1{3} |
\d匹配第一个数字,后面的\1匹配前面\d匹配的内容,重复3次,这样就可以匹配1111或2222这样的4位数字串了。
匹配各种空白
在使用正则时,常用\s来匹配空白,但遗憾的是,还是有一些Unicode的空白字符,\s无法匹配,这时可以尝试POSIX字符类\p{Space},我在Java中验证通过,可以匹配ascii空白字符与Unicode空白字符,如果是其它语言的话,可能正则语法会稍有区别。
位置匹配
正则表达式中\G与环视是比较难理解的,因为这两个东西很多书上只是介绍了匹配的规则,没有说出实质,导致死记的规则过一段时间就忘,也不明白这两东西有啥用。
我们转换一下思维,其实在正则表达式中,匹配目标只有两个,一是匹配字符串中的字符,二是匹配字符串中的位置,如下图: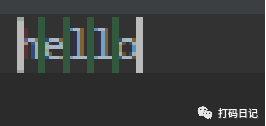
上边的hello,有5个字符可以匹配,另外还有6个位置可以匹配,而^hello中^就是代表匹配开头的位置,所以如果是_hello就无法被^hello匹配,因为_与h之间的位置并不是开头,不能与^匹配!
常见位置匹配规则
| 规则 | 匹配的位置 |
|---|---|
| ^ \A | 匹配开始位置 |
| $ \z \Z | 匹配结束位置 |
| \b \B | 匹配单词与非单词边界位置 |
| \G | 匹配当前匹配的开始位置 |
| (?=a) (?!a) | 正向环视,看看当前位置后面是否是a,或不是a |
| (?<=a) (?<!a) | 逆向环视,看看当前位置前面是否是a,或不是a |
^与\A
^ 匹配文本开始位置,但在多行匹配模式下,^匹配每一行的开始位置。
\A 仅仅只能匹配开始位置,不管什么匹配模式下
$与\Z
$ 匹配文本末尾位置,但在多行匹配模式下,$匹配每一行的末尾位置。\Z 仅仅只能匹配末尾位置,不管什么匹配模式下

\
\\b与\B**
\b匹配单词边界,在Java中,单词边界即是字母与非字母之间的位置,中文不认为是单词,另外文本开头与文本结尾也是单词边界
\B匹配非单词边界

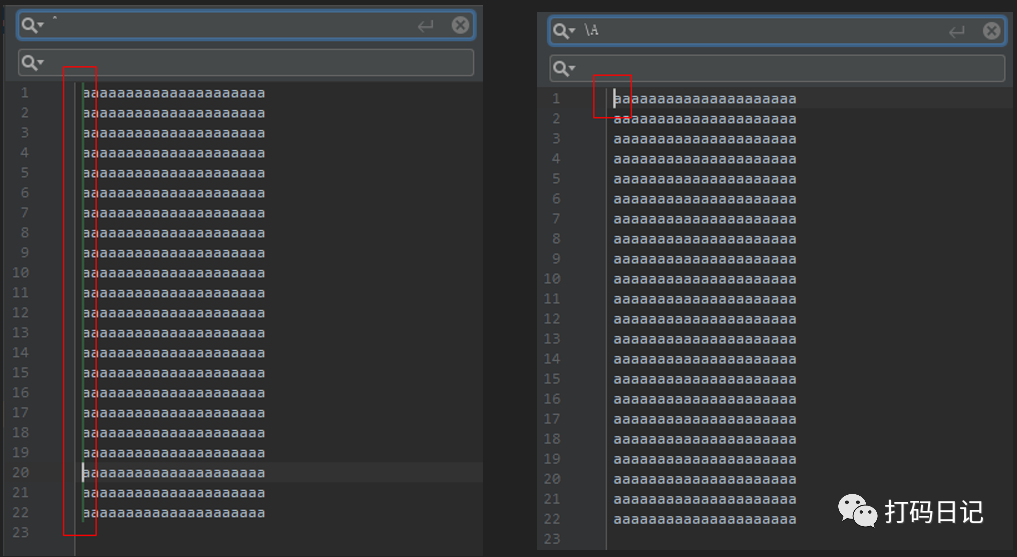
\G
匹配上次匹配的结束位置或当前匹配的开始位置,第一次匹配时,匹配文本开始位置,如下:
从1234a5678中找单个数字,如果用\d去找,可以找到8个,但使用\G\d去找,却只能找到4个
查找过程:
第1次查找,\G匹配文本开始位置,1与\d匹配,找到第1个匹配,即1
第2次查找,\G匹配1后面2前面之间的位置,2与\d匹配,找到第2个匹配,即2
第3次查找,\G匹配2后面3前面之间的位置,3与\d匹配,找到第3个匹配,即3
第4次查找,\G匹配3后面4前面之间的位置,4与\d匹配,找到第4个匹配,即4
第5次查询,\G匹配4后面5前面之间的位置,但a与\d不匹配,匹配结束,总共找到4个匹配。

环视
(?=a) 与 (?!a)
正向肯定(否定)环视,用来检测当前位置后面字符是否是a,或不是a
(?<=a) 与 (?<!a)
逆向肯定(否定)环视,用来检查当前位置前面字符是否是a,或不是a
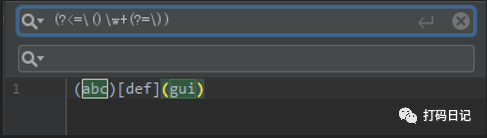
如下,查找被()包裹的单词,使用环视限定单词左边是(,右边是)
位置可被多次匹配
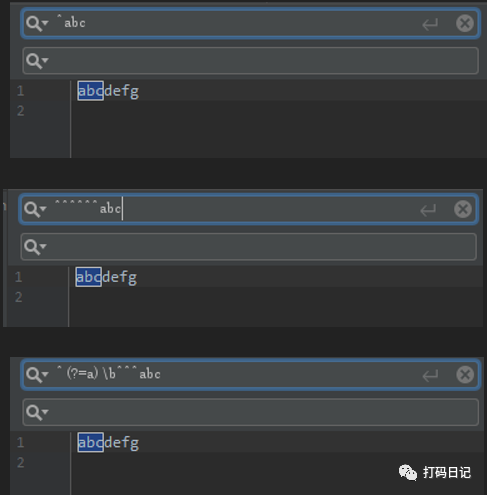
文本中的一个位置,可以同时匹配多个规则,且与规则在正则表达式中的先后顺序无关,例如下面3个正则表达式是等价的:
1 | ^abc |
下面举两个实际例子体会一下位置匹配!
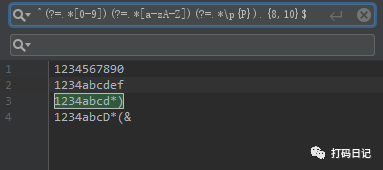
例1:密码强度校验
前端校验密码强度时,经常有这样的要求,长度8到10位,且必须包含数字、字母、标点符号,可通过一个正则表达式校验出来,如下:
1 | ^(?=.*[0-9])(?=.*[a-zA-Z])(?=.*\p{P}).{8,10}$ |
其中,(?=.*[0-9])表示开头位置的后面一定要有数字,(?=.*[a-zA-Z])表示开头位置后面一定要有字母,(?=.*\p{P})表示开头位置的后面一定要有标点符号,.{8,10}表示匹配8到10位字符,这几个正则合在一起,就实现了校验密码强度的要求。
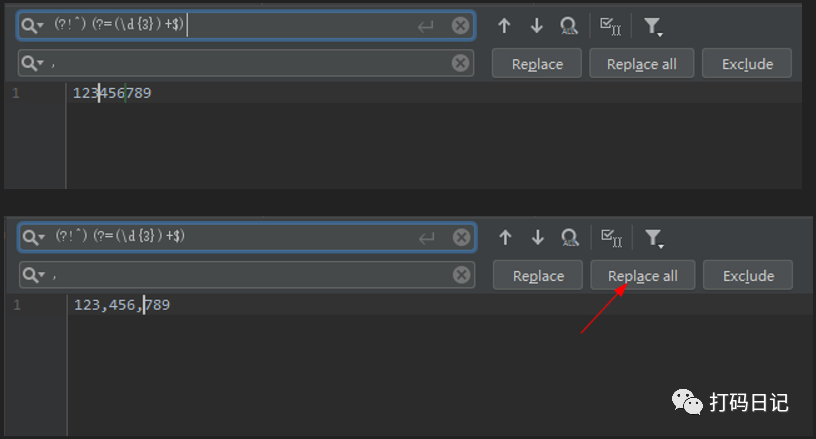
例2:千分位数字
有时我们需要将123456789变成123,456,789这样的千分位数字,这个使用正则就可以实现,如下,将此正则匹配到的位置,替换为,:
1 | (?!^)(?=(\d{3})+$) |
其中,(?=(\d{3})+$)表示匹配位置,这个位置后面必须要有一组或多组3个数字,满足这样条件的位置有3个,开头与1之间的位置,3和4之间的位置,6和7之间的位置,然后(?!^)又限制了同样的这些位置,不能是开头,就只能3和4,6和7之间的位置满足要求了,所以替换之后,就变成了123,456,789。
匹配带引号字符串
匹配诸如"hello,world"这样的带引号的字符串,很容易想到,用"[^"]+"即可,但是如果引号字符串里面允许用\来转义"呢,如"hello \"bob\"!",如果用"[^"]+"来匹配的话,就只会匹配到"hello \"了,显然不对,可以先自行想想如何用正则实现。
…
…
…
想不出来?我们可以换一个视角,包含带\开头转义字符的字符串,其实可以拆解为",hello,\"bob,\"!,",然后再泛化为正则形式,",[^\\"]*,\\.[^\\"]*,\\.[^\\"]*,",组合在一起如下:
1 | "[^\\"]*(?:\\.[^\\"]*)*" |
表达式中多了个(?:),这表示非捕获分组,可以用来提高正则匹配性能,而由于字符串中有可能没有\开头的转义字符,故(?:\\.[^\\"]*)后面是*,直接由[^\\"]*匹配完引号内所有内容。
别搞炸了CPU
正则表达式如果写得很复杂,就需要谨慎评估了,因为有可能平时运行得好好的,但遇到一些特殊情况,会导致CPU直接100%,比如还是上面那个匹配带引号字符串的场景,有同学可能会给出这样的正则:
1 | "([^\\"]+|\\.)*" |
乍一看,这个正则很完美,[^\\"]+匹配非转义字符的部分,\\.匹配\",\n之类的。这个正则在遇到满足条件的字符串时完全没有问题(如"hello \"bob\"!"),而遇到不满足条件的字符串时,正则匹配复杂度会随着字符串长度呈指数式上升,导致CPU 100%,如"hello \"bob\"!!!!!!!!!!!!!!!!!!!!!,其中"没有闭合。
1 | public static void main(String[] args) { |
这段java代码,在我机器上跑完要2s的样子,但如果字符串中再加4个!,运行时间立马上升到17s,性能下降非常恐怖!
原因
如果知道一些正则匹配原理,应该知道正则在匹配时,如果匹配不上,会将已经匹配的字符吐出来,再看看是否能够匹配,这叫回溯,比如".*"匹配"hello",先正则中的"匹配上了字符串中的",然后.*依次匹配了h,e,l,l,o,",最后正则中的"匹配字符串结尾位置,匹配不上,这时正则引擎会让前面的.*吐出它匹配的",然后吐出来的这个",刚好可以和正则中的"匹配,这样就匹配成功了。
那如果是"hello这样没有闭合的字符串,.*会一直吐字符,一直到它没有字符可吐,发现还是匹配不上,这样整个匹配才认定为匹配失败。
是的,正则中包含匹配量词?,*,+时,你就可以想像为它们一直在吃字符,当后面的规则匹配不上时,会强迫它又吐出来,而如果是懒惰匹配量词??,*?,+?,你就可以想像它先不吃,当后面的规则匹配不上时,会强迫它去吃。
我们再来分析下"([^\\"]+|\\.)*"匹配"!!!!!!!!!!!!!!!!!!!!!!!!!!!为啥会如此低效!
注:为了分析方便,我简化了待匹配字符串,但效果是一样的
- 首先
[^\\"]+吃掉了!!!!!!!!!!!!!!!!!!!!!!!!!!!。 - 然后发现正则中
"与字符串结尾位置不匹配,开始回溯。 - 然后
[^\\"]+吐出一个!,注意这里,由于外层还有一个*贪婪量词,吐出来的!又被[^\\"]+|\\.中的[^\\"]+吃掉了,它吃掉后,到了字符串结尾,发现结尾又与正则中的"不匹配,又要求[^\\"]+|\\.中的[^\\"]+吐出刚吃掉的!,结果吐出后又不匹配。 - 然后又逼着最前面的那个
[^\\"]+吐出倒数第二个!,注意,再次吐出!后,当前匹配位置后面有两个!,可恶的是,这两个!又被后面[^\\"]+|\\.中的[^\\"]+吃掉了,然后悲剧重演,它又要吐出来,如此循环往复,计算量指数级上升。
解决办法
其实可以看出来,造成这个问题是因为正则表达式中有两个量词,内层有一个+,外层有一个*,不信的话,你可以尝试用^(a+)*$去匹配aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa0,同样的会非常慢。
而要解决这个问题,有两个办法。
- 让
[^\\"]+吐出来的字符,无法被外层正则中另一个贪婪的自己吃掉,比如前面介绍的"[^\\"]*(?:\\.[^\\"]*)*",[^\\"]*吐出来的字符,是无法被\\.[^\\"]*吃掉的,因为吐出来的一定不是\,而\\.[^\\"]*要先吃一个\。 - 明知道自己吐出来的字符后,后面的规则也无法匹配,那就让量词吃掉字符后不吐,比如将正则修改为
"([^\\"]++|\\.)*"这样,+变成了++,像这种量词后面再加+号的,比如?+,*+,++,这表示占有量词,吃完字符后就不会吐了。
注:占有量词不要乱用,有时吐出来字符可以让整个正则匹配,而你强制让它不吐出来,反而让它匹配不了了,如^.+b$可以匹配ab,但如果你用^.++b$就无法匹配ab了,因为.吃掉了ab,吐出一个b刚好可以使后面的b匹配。而^[^b]++b$这种用法就是对的,因为^b吐出来的字符肯定不能和后面的b匹配,就没必要再吐了。
总结
正则表达式很强大,用好它事半功倍,但也需要了解它的执行过程,避免指数级回溯陷阱。
经验记录
Unicode Regular Expressions
根据Unicode的特征进行匹配,如匹配Unicode表情:/\p{Emoji}/u, 见:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Regular_expressions/Unicode_character_class_escape,仅支持现代浏览器。
更多:https://www.regular-expressions.info/unicode.html#prop
本文链接: http://www.ionluo.cn/blog/posts/9434ed02.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
