阿里云服务器搭建篇
前端监控功能主要包含: JS错误日志监控分析、静态资源请求报错统计、用户行为检索、接口请求报错统计、HTML加载性能分析、PVUV日志分析
好了,现在开始,按照上边的顺序,一步一步搭建前端监控系统。工欲善其事,必先利其器。一个监控系统开发,需要开发环境,部署环境,以及各种开发工具来提高开发效率,那么就先从部署阿里云服务器来说吧,阿里云服务器的部署过程比较漫长,可能不是一天两天能搞得定的,需要有耐心。进入正题。
一、购买阿里云服务器(本地部署类似)
对于之前没有搞过服务器的前端来说,折腾一个能运行的服务器,还真是费了不少周折。
服务器类型: 入门级(共享) 2vCPU 4GB内存 带宽2M(个人建议2vCpu 2GB内存足矣)
安装运行环境:
- 系统: Ubuntu 16 64位 硬盘40G (默认)
- 安装 nvm安装使用教程 , 运行前端项目可能会需要切换node版本,建议提前安装。
- 安装 PM2安装使用教程, 运行node服务应该都知道这个,它是个node服务进程管理器。
- 安装 JDK(Java运行环境),安装tomcat, 并配置环境变量,这个网上教程一大堆。
- 安装 Jenkins安装教程,下载 Jenkins 的war包,在tomcat下运行, 搭建自动化部署系统。 工欲善其事必先利其器,因为会频繁的发布版本,所以这个建议先安装好。
- 安装 Mysql数据库安装教程, 存储数据日志,用于以后的分析。
- 安装 Nginx安装教程,nginx服务器用来做转发,反向代理,以及跨域处理等等。
二、阿里云购买域名
购买阿里云服务器之后,就获得了这个服务器对外的公网IP,通过这个IP和端口,我们就可以访问这台服务器上的服务。 可是无论上传还是访问,总是通过ip有点太不专业了,为了安全,而且很多网站是禁止ip直接访问的,所以,我们需要有一个域名。
申请域名:
这个在阿里云上操作很简单,当然越好的域名就越贵。这里边有一点需要注意,以后有可能给这个域名购买https证书,阿里云上的审核比较严格,有些是无法审核通过的,所以可以先尝试买一个简单的,测试一下,省得花冤枉钱。
域名需要经过购买,备案,准备资料,上传资料,审核,一系列步骤之后,才可以真正使用(步骤繁琐,建议要有耐心)。
域名审核通过后,配置DNS解析,就可以通过域名访问我们的服务器了。
三、购买CA证书或者说是HTTPS证书
现在很多网站都是走HTTPS安全协议,如果我们的服务器不支持安全协议,那么日志是无法被上传到我们的服务器上的。所以我们也需要给我们的服务器配置安全证书。
有多种方式获取证书,有免费的,有收费的,我用的是阿里云上免费一年的。
PS: https证书可能也需要折腾一些时间,需要有耐心。
这样,我们的阿里云服务器部署环境就算搭建完成了,可以开始写前端日志的监控代码了。
JS错误监控篇
监控流程:监控并收集错误 -> 存储并上报错误 -> 分析并聚合错误 -> 发送错误报警-> 定位并解决JS错误
一、监控并收集Javascript错误
众所周知,我们是有办法去监听前端Js错误的,他们分别 window.onerror、window.onunhandledrejection、console.error方法。
通过这些方法能够为我们记录下线上的运行时错误,以及详细的堆栈信息。我将window.onerror(捕获异常),console.error(自定义异常)方法收集到的错误信息进行分析统计后的效果如下: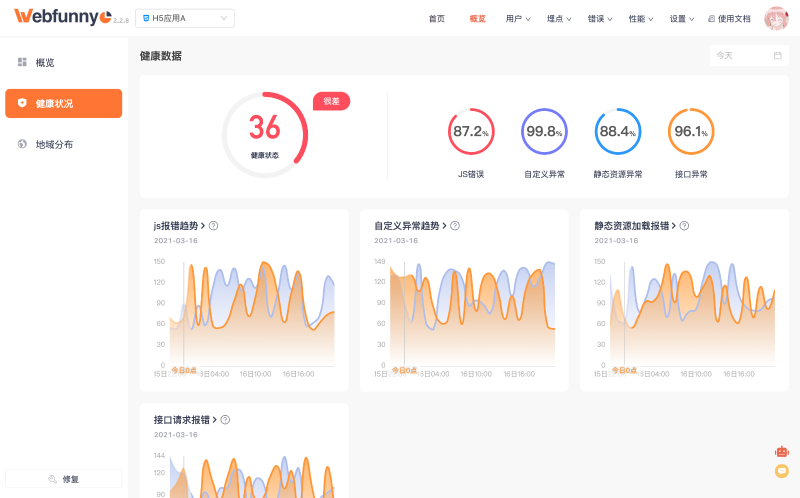
(1)重写 window.onerror 方法
1 | // 重写 onerror 进行jsError的监听 |
window.onerror 方法以及它的参数我就不一一介绍了,我相信大家也已经耳熟能详了;我们记录下错误发生时的行、列号,以及错误堆栈。
(2)重写 window.onunhandledrejection 方法
1 | window.onunhandledrejection = function(e) { |
window.onunhandledrejection 能够捕获到Promise未处理的rejection异常,rejection异常并不会阻断页面运行,容易被很多小伙伴所遗忘,所以我们监控了此类型的错误。
(3)重写 console.error 方法
1 | // 重写console.error, 可以捕获更全面的报错信息 |
console.error 是用来打印警告日志,所以我将其归类为自定义异常。一般像前端框架、引入第三方的插件都会用 console.error 来打印较为严重的警告信息,而我在工作中也会将后台抛出的错误信息(非后台异常)用console.error打印出来,上报到监控系统里。这样对排查异常也是有很大作用的(这一点会在行为记录查询中有体现)。
二、存储并上报错误
Javascript错误产生后,应该存入浏览器的缓存中,然后定时上传,如果实时上传,将会对服务器造成压力。通过接口将Js错误信息上传到服务器,由后台server对数据进行清洗分类,然后再进行持久化存储。因为我用的是mysql来存储日志信息,所以需要以JS错误为一个model,明确定义Js错误的每个字段,定义如下:
1 | // 设置日志对象类的通用属性 |
Js错误信息需要包含系统版本号、应用版本号、平台信息、页面Url、错误信息、错误堆栈、发生时间等等,这样才能帮助我们准确定位,至于数据库的字段如何定义,我就不赘述了,可以访问我的git项目查看。
三、分析并聚合错误
如果每天都去盯着前端的报错数据,真的很耗费精力,而且很难看出是今天发生的,还是一直存在的报错。
其实前端项目每天都会有些报错,比如:script error 。我们既不能控制,也不会影响我们的业务,但它会一直存在。
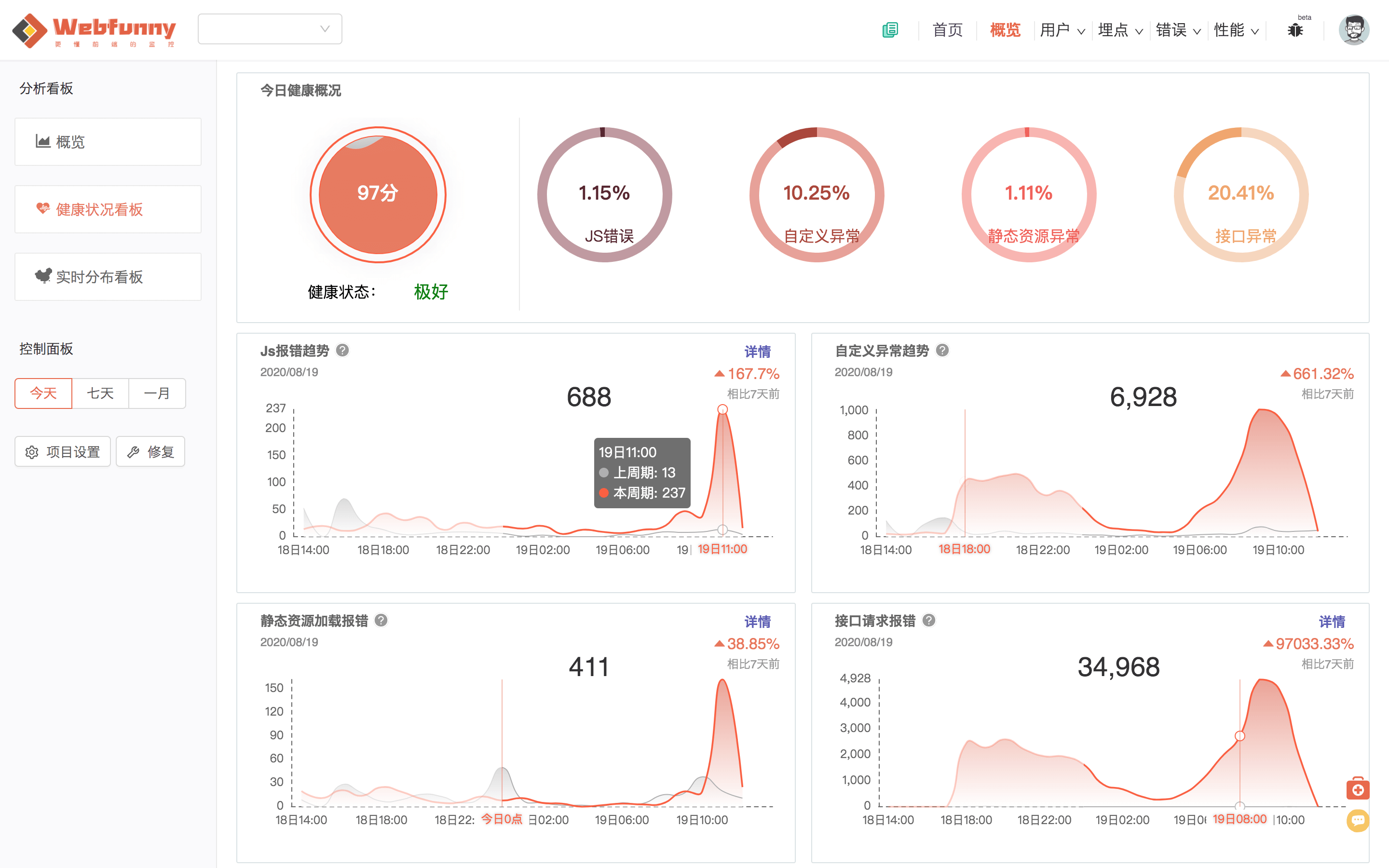
只要每天的错误量没有波动太大,报错数据比较平稳,就可以认为线上应用是健康的。所以我选择跟一周前的数据进行比较,如果出现大幅上升,那么就需要对这个项目进行关注了,而不是每天查看具体的报错数据。
本文上部的健康状况看板图片就是为了表达这种想法,截图上正是前端发了严重的异常,而出现的曲线图。
那我们来看看如何对这些错误进行聚合,且看下Webfunny错误聚合的效果: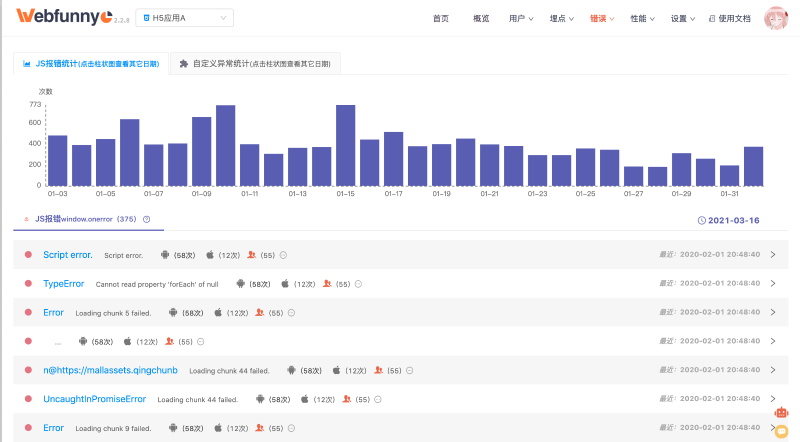
首先,我们对捕获的异常类型进行了分类(TypeError、ReferenceError、UncaughtInPromiseError),这样错误类型可以一目了然。
同时我们对发生错误的操作系统(Android、ios、Pc)进行了分类统计,比如截图中的第一个错误,就只会在苹果手机上发生,排查范围也就缩小了很多。
另外,我们把错误影响的人数也统计出来,就可以知道这个错误影响了多少用户,从而确定修复的优先级。
四、发送错误报警
这一步属于监控的附加功能,主要包括邮箱、钉钉、短信等消息通知,和本次讲得知识点无关,我就不细说了。
五、如何定位并解决JS错误
针对某一个错误,我们需要分析它发生的平台,影响的人数,系统版本,网络环境等等,同时也需要分析最为重要的一步,就是代码的位置。
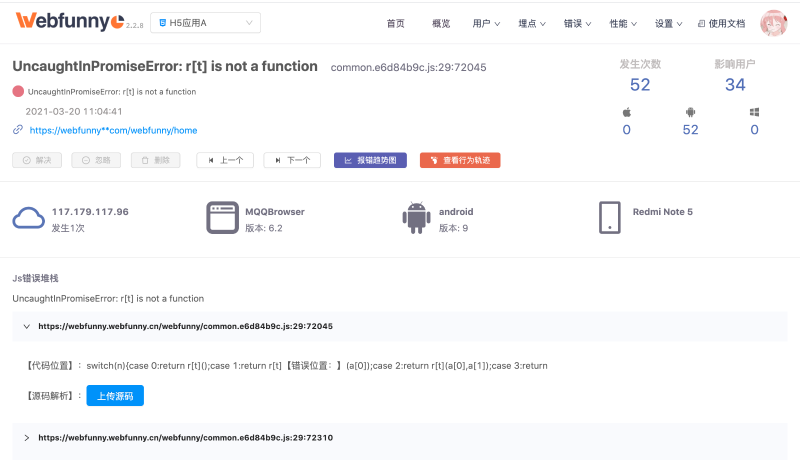
如图所示
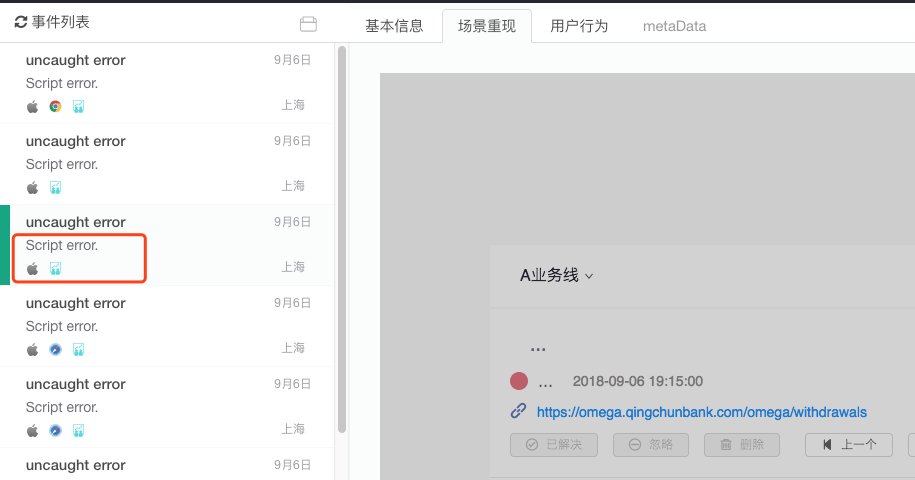
首先,我们分析了错误发生的具体时间、发生次数、影响人数、IP地址、浏览器版本、操作系统等环境因素
其次,我们还需统计这个报错发生的时间曲线,如果是大量报错,我们可以很容易定位到错误发生的起始点,针对那个时间点,对报错的原因进行定位
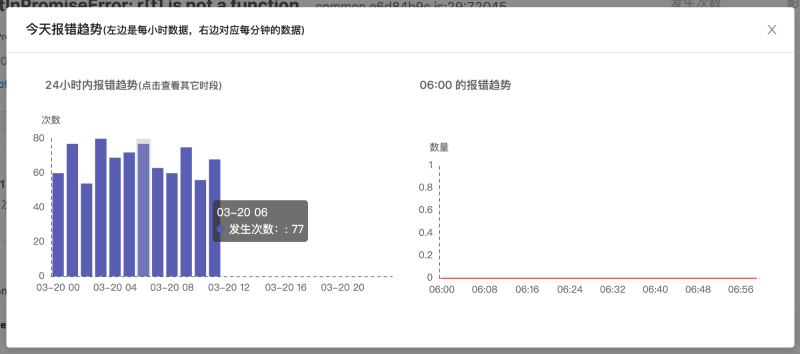
还有一个重要的点,就是对代码代码堆栈的分析。我们默认会根据错误提示的行、列号截取错误位置附近的一段代码,正常情况下,我们已经可以通过这段代码来定位出出错的具体位置了。
但是有些小伙伴说,我就是看不出来怎么办,没关系,我们还提供了利用Js的SourceMap文件反向定位源码的功能,让你准确定位到Js源码的位置。
PS:由于SourceMap文件反向定位源码的功能较为复杂,我将放到下一个知识分享中进行讲解。
最后,我们将Js错误结合到用户的行为记录中,这样我们就能够知道用户在发生错误的前后都做了什么,更进一步的了解错误发生原因,错误详情页提供了查看行为轨迹的按钮,我们来看看结果。
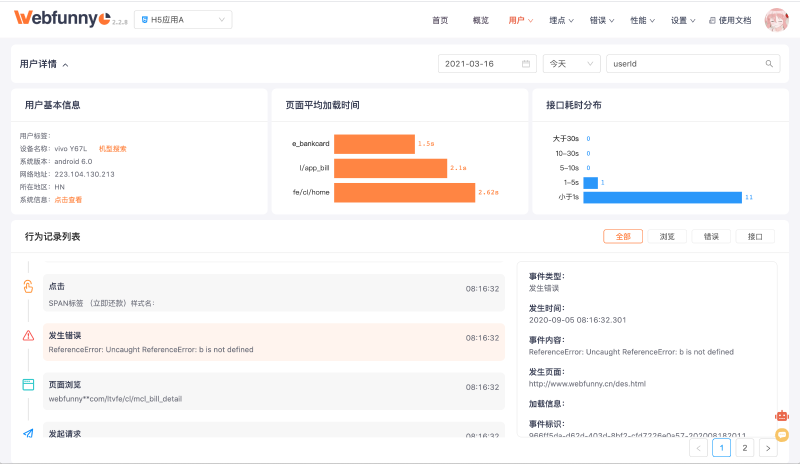
好了,说了这么多方法,对Js错误的监控和解决方法已经不再是什么难事了。****
静态资源加载监控篇
上一章介绍了如何做JS错误监控,还有一种错误是静态资源加载报错,很多时候资源加载报错对前端项目来说是致命的,因为静态资源加载出错了,有可能就会导致前端页面无法渲染,用户就只能对着一个空白屏幕发呆,不知所措。因为突然有一天,我们的线上环境爆出了大量的白屏错误,经过很长时间的排查,终于定位到问题原因:我们使用的CDN路径不知道怎么的,把我们的https协议全部指向了http协议,在安全协议下无法访问非安全协议的资源,导致了大量的白屏。所以我决定增加静态资源监控功能,以应对未来的未知情况。
那么,下边我们就进入正题:
如何监控前端静态资源加载情况
正常情况下,html页面中主要包含的静态资源有:js文件、css文件、图片文件,这些文件加载失败将直接对页面造成影响甚至瘫痪,所有我们需要把他们统计出来。我不太确定是否需要把所有静态资源文件的加载信息都统计下来,既然加载成功了,页面正常了,应该就没有统计的必要了,所以我们只统计加载出错的情况。
先说一下监控方法:
1)使用script标签的回调方法,在网络上搜索过,看到有人说可以用onerror方法监控报错的情况, 但是经过试验后,发现并没有监控到报错情况,至少在静态资源跨域加载的时候是无法获取的。
2)利用 performance.getEntries()方法,获取到所有加载成功的资源列表,在onload事件中遍历出所有页面资源集合,利用排除法,到所有集合中过滤掉成功的资源列表,即为加载失败的资源。 此方法看似合理,也确实能够排查出加载失败的静态资源,但是检查的时机很难掌握,另外,如果遇到异步加载的js也就歇菜了。
3)添加一个Listener(error)来捕获前端的异常,也是我正在使用的方法,比较靠谱。但是这个方法会监控到很多的error, 所以我们要从中筛选出静态资源加载报错的error, 代码如下:
1 | /** |
我们根据报错是的e.target的属性来判断它是link标签,还是script标签。由于目前我关注对前端造成崩溃的错误,所以目前只监控了css,js文件加载错误的情况。
首先,我们要做实时监控和预警,依然关联了7天以前同一时间端的数据,如果某个时间段出现错误量暴增,可以发出警告,及时制止。
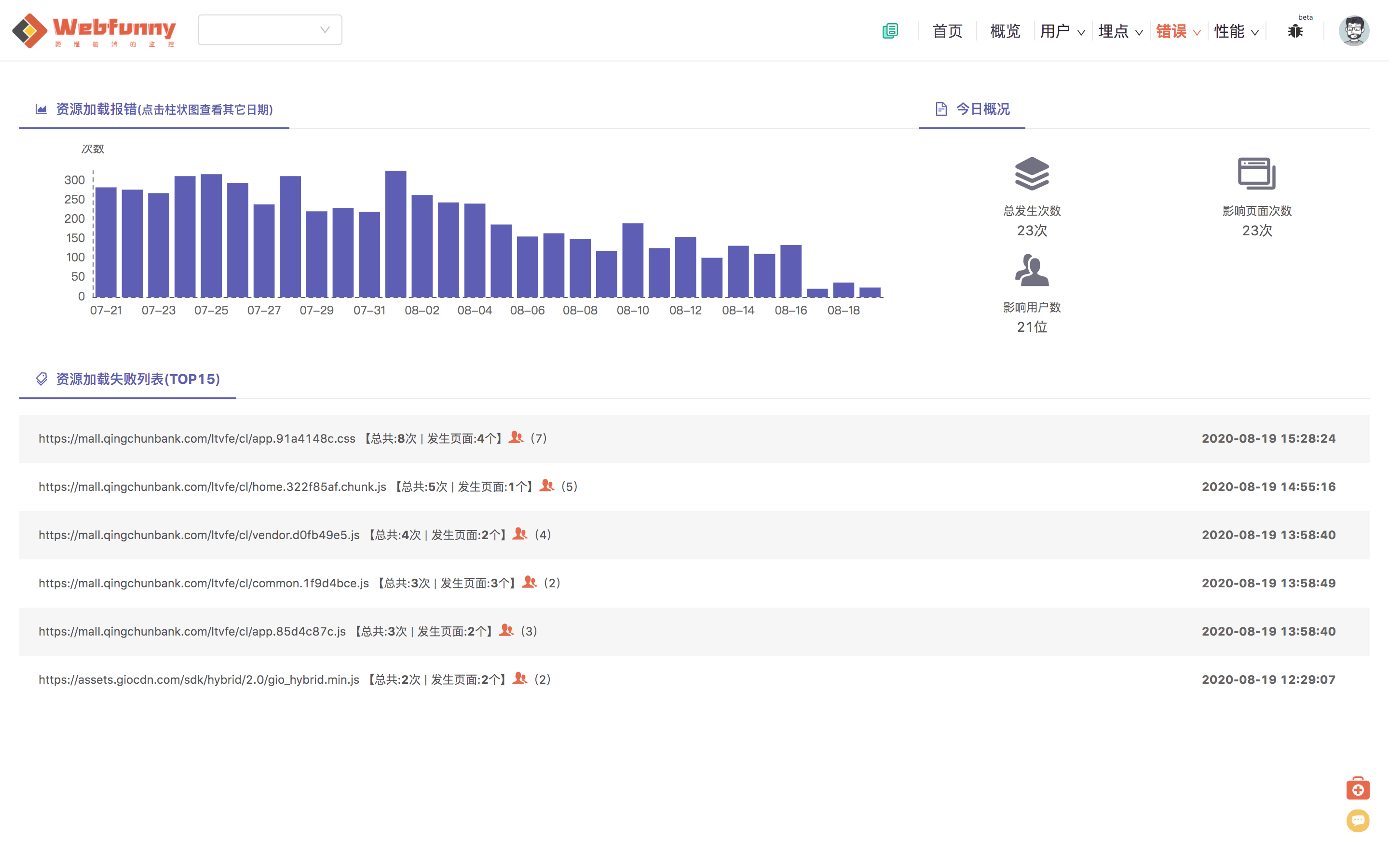
然后,我们还需要知道更多详细的信息,如下图。 不看不知道,一看吓一跳。虽然线上环境并没有给我们报出这么多的问题,但是可以看到,每天还是有很多的静态资源加载报错,有些是很重要的静态资源文件,是必然会导致页面渲染失败的,所以必须要解决。
解决方案:
① 统计出每天的量,列出每天加载报错的变化,点击图表的bar, 可以看到每天的数据变化,以作对比。
② 分析出静态资源加载出错主要发生在哪些页面上,缩小排查的范围。
③ 分析出影响用户的人数,也许很多错误就发生在一个人身上,减少盲目排查。
静态资源加载监控就完成了, 这里还有一些细节需要处理, 来帮助排查问题, 但是我一时半会儿也想不出来,暂时就说到这里吧。
Js截图上报篇
用户对前端程序员来说,就是一个黑匣子。 如果用户上报了一个错误,前端程序员就是两眼一抹黑,因为很多错误是没法复现的。我问过很多前端工程师,他们的回答都是,如果你没法复现Bug,我怎么去解决这个Bug呢。 那么有没有一个办法可以解决用户和前端程序员之间的障碍呢, 让用户对我们来说,不再是黑匣子,而是透明化。用户的页面长什么样,他们都做了什么操作,发生了什么错误,我们都能够清晰的知道,那么,再有问题上报的时候,我就会很有信心的说一句: I Can Fix it !
最近试用了一下Fundebug,进入首页,第一条便是 黑科技!支持录屏。 这下就惊呆我了,js做前端监控,居然还能录屏? 你丫这是要逆天啊? 所以,赶紧注册了账号,进行试用。
经过各种配置后,进行测试发布,发现毫无效果,所以询问客服。 回答是: 目前录制功能有bug,所以默认为关闭状态,将配置属性silentVideo设置为false即可。

果不其然,经过客服的细心指导,终于成功了。 图一为电脑版chrome浏览器,可以正常进行屏幕录制。 图二为手机app自带的webview浏览器,第一次点击显示灰屏,第二次点击显示为电脑版的录屏。经过测试,除了chrome之外,其他浏览器均不支持。这让我想起一个可以进行js截屏的库JSCapture, 也是只支持chrome浏览器的。我猜想,Fundebug用的应该就是这个黑科技。 Fundebug也表示并非真的视频,应该是多做了几帧截屏,然后顺序切换,看着像视频了。
虽然是黑科技,但是也面临着几个比较大的问题:
一、因为支持的浏览器只有chrome,而chrome又是兼容性做得最好的浏览器了,很多问题在这个浏览器上根本不会发生, 所以这个黑科技还是有待来日,也许会得到更多浏览器的支持之后,才能真正的发挥作用。不得不感慨一句:唉,兼容性-前端程序员一生的宿命。
二、就算屏幕录制解决了,上传了一个至少有个几帧的仿视频,这个流量大小可是很严重问题了,虽然Fundebug说是经过特殊处理压缩后,一个视频只有几十KB,我总觉得不是很靠谱,感觉比较难以实现(待验证)
三、我自己的手机是iphone6 Plus, 当Fundebug在我的手机上进行屏幕捕捉的时候,手机都会卡顿很久。 我之前曾尝试在iphone6上用js进行截图,但是也会出现卡顿现象,这一点在微信浏览器上表现极为明显,甚至会导致微信重新刷新页面。 好在iphone6以上的版本,截屏的效率都很高,不会再出现卡顿了
所以,Fundebug的黑科技是不能够普及的,但是我们可以换个思路来记录用户的行为。
之前,我曾经考虑过一个需求,记录下用户的每个行为,访问页面的截图,点击按钮的局部截图,这样,在错误发生的时候,就能清清楚楚的知道用户在页面上做了什么,但是由于截图上传需要耗费的流量确实太大,所以这个想法不得不放弃了。 今天,我看了Fundebug的黑科技,却给了一些启发。 我将针对以上提出的三个难点,完善页面上用户行为追踪功能。
用户行为追踪功能
一、 上传截图,流量消耗过大怎么办,对图片资源进行极致压缩。
进行截图后,需要上传的数据很大,因为是图片数据,多则大几百Kb, 少则也有个上百Kb, 这么大的流量,对用户端,损耗确实过大。
首先,对js截图进行了几种测试,如图:
以上截图方式的参数如下:
参数 截图方式一 截图方式二 截图方式三
压缩前/后长度 28764/10787 93076/34903 168312/63118
图片压缩率 72% 40% 0%
截图大小 21Kb 68.2Kb 123Kb
综上分析,截图方式一, 压缩率高,虽然截图不是很清晰,但是,也能够看得出,线上用户页面是什么样子的。
而且,也解决了,在低端机上截图消耗性能过大的弊端,二十几Kb的流量,也是我们完全能够接受的大小了。
由此可见,该方式能够完全能够满足我们追踪用户行为的需求。
二、如果用户量非常多, 用户频繁的上传,也是一个大问题
所以,我的建议是分散流量,让每个用户为我们贡献至少一次页面截图:
① 每个用户都在随机的页面,随机的时间上传一个页面截图,以及一个点击区域截图,有且仅上传一次,一个用户的生命周期中只贡献一次页面截图
② 每个用户发生某一类错误时,也只需上传一个截图即可,多个类型的错误,则上传多个截图。这样可以大量节省用户的上传次数。
③ 用户的截图数据很大, 时间长了需要很大的硬盘空间, 所以我的建议是,每个流程页面,只需要对应一个(点击区域截图,同理)。 每个用户的某一种类型的错误页面也只对应一个(方便定位错误原因)
如何截图,如何压缩上传资源的大小
1 | /** |
要做成这件事,必须依赖两个js库的帮忙了。
html2Canvas 执行html页面截图, lz-string 执行对字符串长度的压缩,使用方式,如上方代码所示。
由于用户行为追踪功能可以由使用者选择性开起, 所以,建议这两个js库文件有客户端引入, 这样就可以减少探针代码的大小, 如此,我们就需要定义一个加载js文件的小工具
1 | // 加载js文件的小工具this.loadJs = function(url, callback) { |
OK, 数据都已经准备妥当,剩下的就是要把这些数据存储起来,并和用户行为,以及js错误关联起来。 完成用户行为追踪功能。
用户行为统计和监控篇(如何快速定位线上问题)
一直以来, 前端上线的项目,对于前端程序猿来说,完全是一个黑盒子。 项目一旦上线,我们完全不知道用户在我们的项目里边做了什么,跳转到哪里,是不是报错了。一旦线上用户出现问题,而我们又无法复现的时候,才能体会到什么叫绝望。 不管多么艰难,问题总是会在哪里等着你。所以,如果我们可以把线上的项目变成一个白盒子,让我们能够知道用户在线上干了什么,复现不再困难了,对前端程序员来说,是不是一件好事呢。
接下来我要写的是一个重要的功能, 因为它极大的提高了我解决问题的能力, 也让对我的工作产生了很大的影响。
截止到现在,来看看我已经完成了哪些功能:
PVUV的统计上报,js错误的上报和分析, 接口的统计上报,页面截屏的统计上报。 那么,再补上今天要写的“用户点击行为的上报”, 我们基本上就能够分析出一个用户在页面上干了什么。
一、如何记录线上用户的行为
线上用户的基本行为包括: 访问页面, 点击行为,请求接口行为, js报错行为, 这几点基本上能够清楚的记录下用户在线上的所有行为。 当然还包括:资源加载行为,滚动页面行为, 元素进入用户视野等等行为,这些是更为细节的行为统计, 也许会在以后进行完善, 但是以上的四种行为已经可以完成我们的统计需求。
访问页面, js报错行为我们已经有了,接下来看看如何统计点击行为和请求接口的行为吧。
点击行为:
1 | // 用户行为日志,继承于日志基类MonitorBaseInfo |
我们先来看一下点击行为的代码,其实很简单,就是重写一下document的onclick方法,然后把相应的元素的属性,内容等等保存起来, 但是,我们费了这么大的力气保存了如此多的日志,就为了简单的记录一下用户的点击行为,实在太浪费了。 所以,这个点击行为统计会被添加到未来的留存分析当中去,到时候能够实现无埋点记录日志的功能,让我们的监控系统更加的强大和丰富。留存分析会参考GrowingIo, 有兴趣可以了解一下。
我们需要记录下元素的className, tagName, innerText等等,我们需要足够的的内容才能够确定用户点击的是哪个按钮。这种方式比较弱智,将会在以后写留存分析功能的时候进行完善一下,但是目前足以满足我们的要求了。
请求接口行为:
1 | // 接口请求日志,继承于日志基类MonitorBaseInfo |
让我们来看看接口行为统计的代码先,本来这个我想单独拿出来说一说的,但是现在么有那么多时间把它相关的功能开发出来,所以只写了一个简版的。
接口行为的统计包括: 发起请求,接收请求,接收状态,请求时长, 通过前端对接口的统计和分析,我们是可以观察出线上接口的质量,同时也能够对前端的逻辑做出相应的调整,已达到页面加载的最佳效果。 数据库字段定义都在分析后台的项目里, 可以直接去看。
首先,我们要监听页面的ajax请求, 如上所示,写了一段监听ajax请求的代码(我是在网上扒下来的 thanks), 可以监听到页面上所有的ajax请求,对整个ajax请求过程进行了原子性分析,我们可以监听到请求过程中任何一个时段的事件,非常好用。 但是,有一点非常重要, 如果你的项目里边用的是fetch请求数据的话, 那么这些监听就无效了。 因为fetch代码是浏览器注入的, 肯定先用监控代码执行,然后你再监听ajax就一点用都没有了。 所以你需要在写好ajax监听之后,重写fetch代码, 这样就可以生效了。好了,这部分并不是这篇幅的重点,我们就说到这里。
二、如何查询线上用户的行为
终于,我们把剩下的两种行为记录都成功上传了,那么该如果把他们都查询出来呢。我们先来看一下页面上我查询出来的结果。
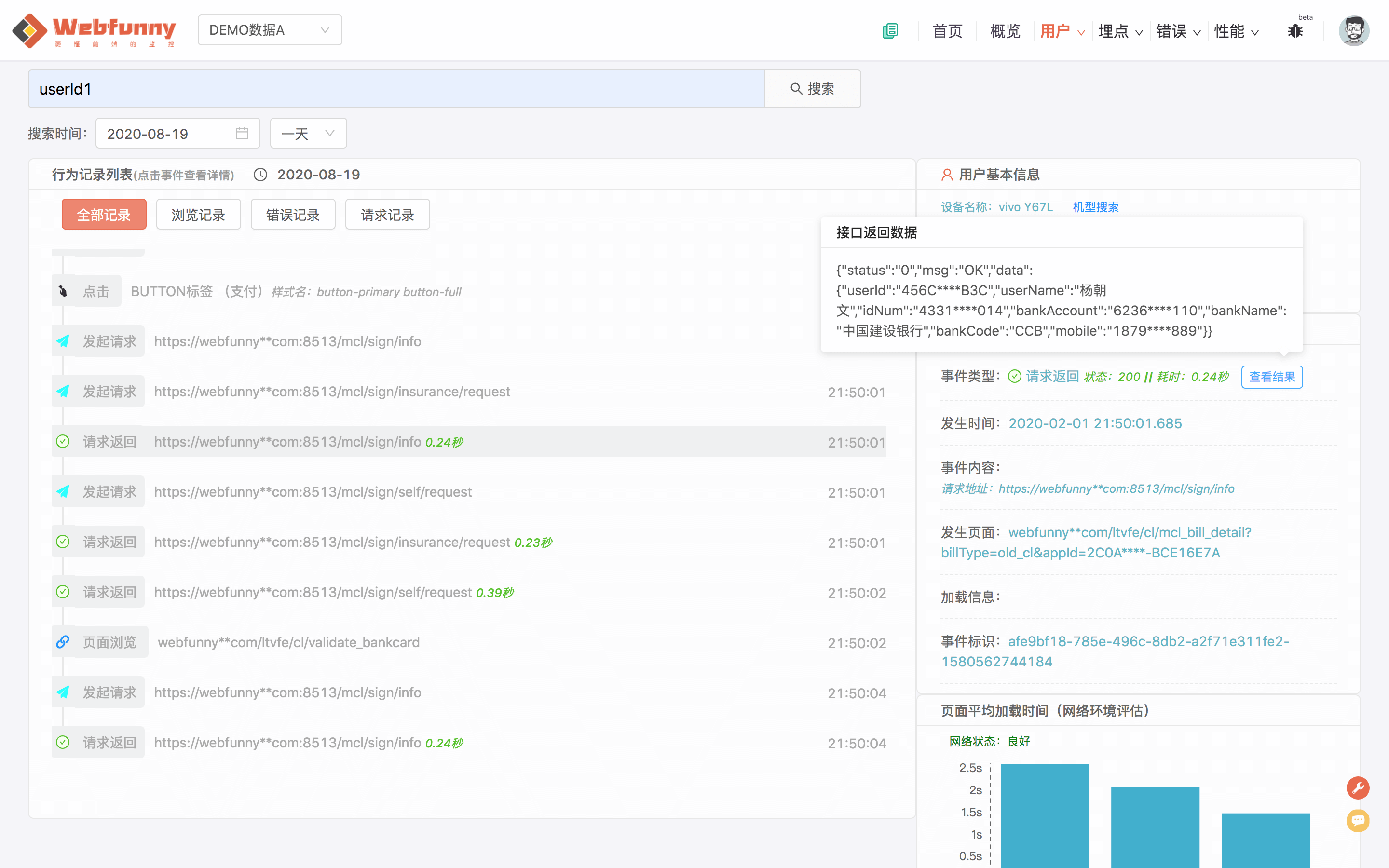
因为屏幕太小,无法展示所有的记录,记录信息包含:行为名称,行为发生时间, 行为发生页面, 错误信息, 错误截图, 以及用户自定义上传截图的时机。
说到这里有几个小问题需要注意。
因为是用Js做探针,记录日志的时候很难保证每次记录都可以把用户的userId插入进去
所以我们给每个用户都定义一个customerKey来做区分,如果用户不卸载app和清理app的缓存, customerKey将保持不变
在查询用户的行为记录的时候,需要先查询出用户所有的customerKey(可能有多个),再用customerKey进行查询,便可以得到准确的结果。
三、如何分析线上用户的行为
其实我们做了这么多,记录了这么多,就是为了这个目的:分析行为,快速定位问题。
那么我们如何定位问题呢,我可以举例说明一下:
- JS报错阻断行为,我们可以看到发生错误的前后行为,就能够快速准确定位问题。
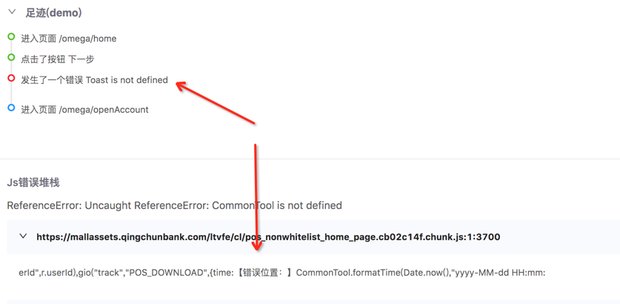
复杂的链接跳转发生了错误。有些错误是前端页面会经过复杂的跳转,回退之后才发生的,就算测试人员也很难测试出这种问题,因为线上的用户的任何行为都有可能出现。往往我们知道的只是他在最后停留的页面发生了错误。 如此,经过我们排查行为日志, 就能够复现出用户的行为, 从而复现BUG
接口异常。 正常情况下,前端的接口都会设置超时时间的, 但是呢, 后台接口排查发现正常, 而前端就是无法正常执行, 这种问题没有显示的错误现象,而线上的反馈并不能够准确,前端只能背锅了。 而日志记录是可以把请求发出时间和返回时间记录下来, 是否超时,看一眼就知道。
线上的用户根本就不会反馈异常, 他们能做的只是把最后一眼能看到的东西告诉你。 天知道他们之前经历了什么步骤。 最终的结果是,前端有问题,然后背锅,哈哈。
总之, 我们知道用户在页面上干了什么, 便不再担心问题出现, 遇见问题也不会再手忙脚乱了。
其他
Angular1 对 JavaScript 运行时错误的处理
在 Angular1 中,uncaught exceptions 会被在 $exceptionHandler service 集中处理,并通过 console.error() 将报错信息输出。
1 | // https://github.com/angular/angular.js/blob/master/src/ng/rootScope.js |
这意味着,Angular1 中的运行时错误,将不会被 window.onerror 捕获。
好在可以改写 $exceptionHandler service ,使其可以被 window.onerror 捕获。
1 | // https://rollbar.com/blog/client-side-angular-error-handling/ |
然后这样使用:
1 | var myModule = angular.module('myApp', ['exceptionOverride']) |
以上文章原文链接在标题中可见
本文链接: http://www.ionluo.cn/blog/posts/9d2bf2a2.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
