文档
https://wkhtmltopdf.org/usage/wkhtmltopdf.txt
问题
Exit with code 1 due to network error: ContentNotFoundError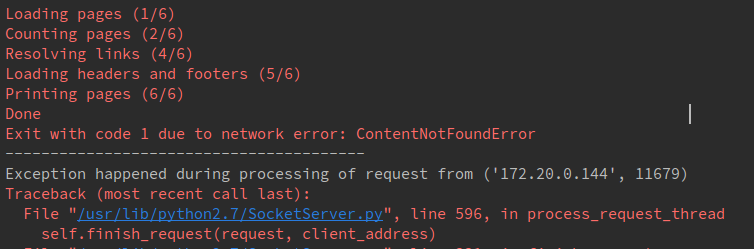
原因是:此异常为是因为引用了外部的资源,如:字体,图片,iframe加载等。检查对应的外部资源是否可以加载。
returned non-zero exit status 1
绝大多数报错都是返回这个的,需要在服务器上执行下这个命令拿到更详细的报错信息:
1
/var/www/beta_bio_cyagen_net/bin/wkhtmltopdf/0.12.3/wkhtmltopdf-amd64 --enable-local-file-access --encoding utf8 --footer-html /tmp/wkhtmltopdfNy5zuH.html --header-html /tmp/wkhtmltopdfGmy8DK.html --margin-bottom 10 --margin-top 16 --margin-bottom 10 --margin-top 15 --page-size A3 --quiet False /tmp/wkhtmltopdfRBSsIs.html -

可以看到,这里是权限拒绝,命令前面加上
sudo, 输入root密码再执行一次。
这个问题看了GitHub,没有什么头绪。先看下是否可以打印网页,
1
sudo /var/www/beta_bio_cyagen_net/bin/wkhtmltopdf/0.12.3/wkhtmltopdf-amd64 'https://www.baidu.com' /tmp/baidu.pdf
依旧如此:

这很令人疑惑,查看下系统信息和软件版本:
1 | cyagen@QhBetaBio:/$ lsb_release -a |
发现Ubuntu被运维升级成了18版本,之前也是18版本系统运行不了这个版本的软件。
封面无法去除页边距
封面参数需要移至全局参数之后
- 图片无法加载
情况一:图片链接被置换成
file///xxx截图如下:

可以看到,原来的链接被替换多了
file///xxx, 具体原因不详,应该是django-wkhtmltopdf插件导致。解决方法:修改图片位置,不要放到
static的路径下,我这里放到了media目录下即可。情况二:图片过大导致的无法显示。
这个情况其实我也不确定是否图片过大导致,只是一个猜测。
解决方法:设置一个延时(
javascript-delay),让图片有更多的加载时间。1
2
3WKHTMLTOPDF_CMD_OPTIONS = {
'page-size': 'Letter', 'margin-top': 16, 'margin-bottom': 10, 'javascript-delay': 1000,
}情况三:无法引用本地图片。
检查下是否有加
--disable-internal-links配置。有一个万精油的解决方案就是:把图片转base64嵌入html
打印的信息不够详细
如上图,打印的信息只有命令和错误码1,这里错误码1代表命令执行出错或者包不存在。具体错误原因丢失了,因此,需要打印出具体的报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41# wkhtmltopdf > utils.py
from .subprocess import check_output, CalledProcessError
import subprocess
# 重定义CalledProcessError类
class MyCalledProcessError(CalledProcessError):
"""This exception is raised when a process run by check_call() or
check_output() returns a non-zero exit status.
The exit status will be stored in the returncode attribute;
check_output() will also store the output in the output attribute.
"""
def __str__(self):
return "Command '%s' returned non-zero exit status %d\n\n\n%s" % (self.cmd, self.returncode, self.output)
def wkhtmltopdf(pages, output=None, **kwargs):
……
ck_kwargs = {'env': env}
# Handling of fileno() attr. based on https://github.com/GrahamDumpleton/mod_wsgi/issues/85
try:
i = sys.stderr.fileno()
ck_kwargs['stderr'] = sys.stderr
except (AttributeError, IOError):
# can't call fileno() on mod_wsgi stderr object
pass
# 开始修改的地方
try:
return check_output(ck_args, **ck_kwargs)
except CalledProcessError as e:
# 要捕获错误输出,需要将另一个参数传递给subprocess.check_output()函数。您需要设置stderr=subprocess.STDOUT。这将把stderr输出传送到e.output。
# https://www.cnpython.com/qa/246345
ck_kwargs['stderr'] = subprocess.STDOUT
# 捕获错误,用自定义类来返回错误信息
try:
return check_output(ck_args, **ck_kwargs)
except CalledProcessError as e:
err = MyCalledProcessError(e.returncode, e.cmd, e.output)
logger.error(err.__str__())
raise MyCalledProcessError(e.returncode, e.cmd, e.output)最终效果如下:

TypeError: expected string or buffer
数据不是字符串,这里和插件无关,仅为记录。
本文链接: http://www.ionluo.cn/blog/posts/9d50cee6.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
