html→word
方式1:html-docx-js
1、npm安装
1 | $ npm install --save html-docx-js |
2、引入
1 | import htmlDocx from 'html-docx-js/dist/html-docx'; |
3、点击事件实现导出
1 | <template> |
4、带预览的下载
1 |
|
关于canvas的踩坑,推荐阅读:https://juejin.cn/post/6844903855214297102
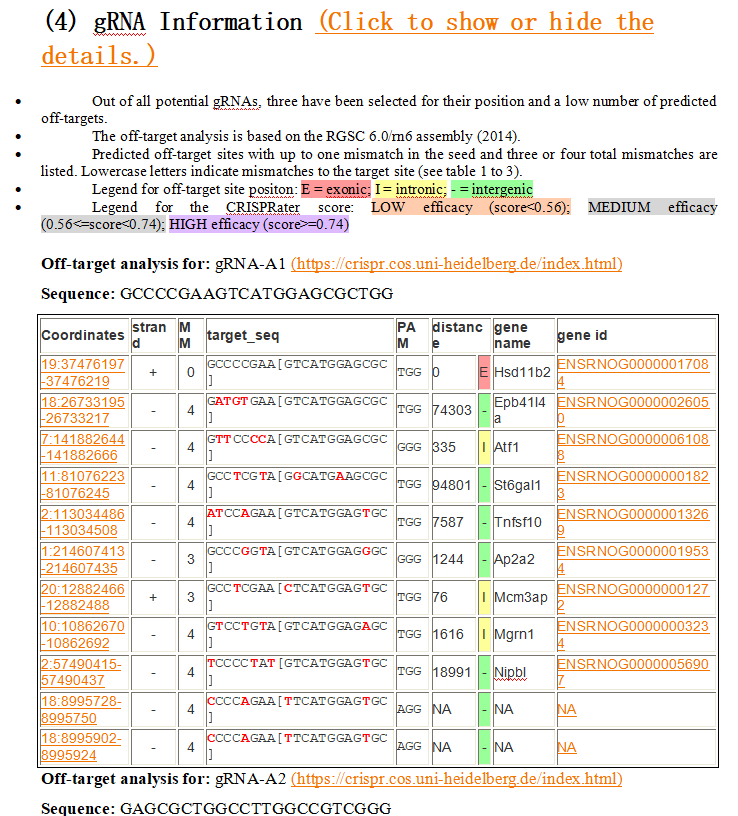
效果如图:
方式2:pandoc
ubuntu安装:
1 | sudo apt install pandoc |
官网:pandoc 通用文档转换器
更多:【解锁】Pandoc——Pandoc安装、使用、快速上手
官网: pypandoc 1.5
示例代码:
1 | # !/usr/bin/env python |
扩展阅读:
注意:该插件不支持pdf→word
**问题1:Stack space overflow: current size xxx bytes. **
1 | # Stack space overflow: current size 33624 bytes. |
**问题2:效果不好,样式无法设置,除了文字的样式还算ok,其他都不太行。 **
方式3:LibreOffice
1 | # Ubuntu安装libreoffice(windows上见https://blog.csdn.net/weixin_34032779/article/details/86022062) |
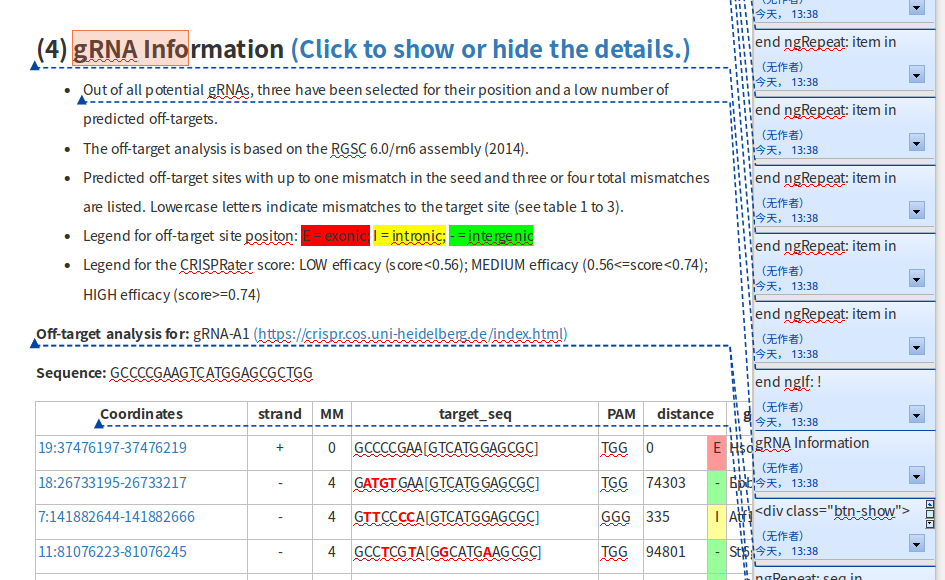
效果:
word→pdf
方式1:Office+win32com
该方式只适用于window系统,且有安装office(测试WPS也可以)。
1 | # -*- encoding: utf-8 -*- |
pdf→word
方式1:pdfminer+python-docx
原理是通过pdfminer提取文字,通过python-docx存入docx。因此仅仅适合带文字的PDF。
依赖插件:
1 | # vim requirements.txt |
python代码:
1 | # # -*- coding: utf-8 -*- |
效果:

方式2:LibreOffice
1 | # Ubuntu安装libreoffice(windows上见https://blog.csdn.net/weixin_34032779/article/details/86022062) |
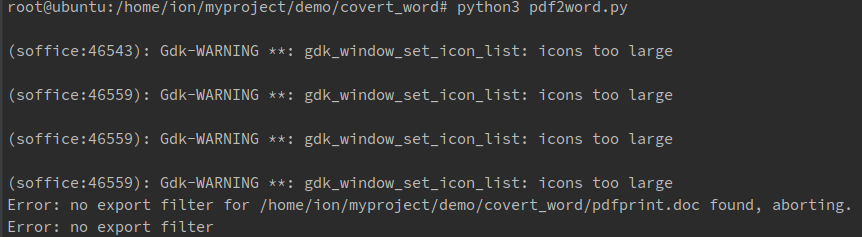
问题:无法执行,缺少过滤器,截图和说明见:
原因分析:
1 | This is not a bug. Using --convert-to includes normal opening a document |
纠正代码:
1 | # # -*- coding: utf-8 -*- |
参考:https://www.mail-archive.com/libreoffice-bugs@lists.freedesktop.org/msg559573.html
总结:
效果是比较好的,但是转docx还是会出现格式混乱的问题。同时在wps中页面有一定的偏移,在桌面版Ubuntu的LibreOffice Writer中打开会卡死,原因未知。
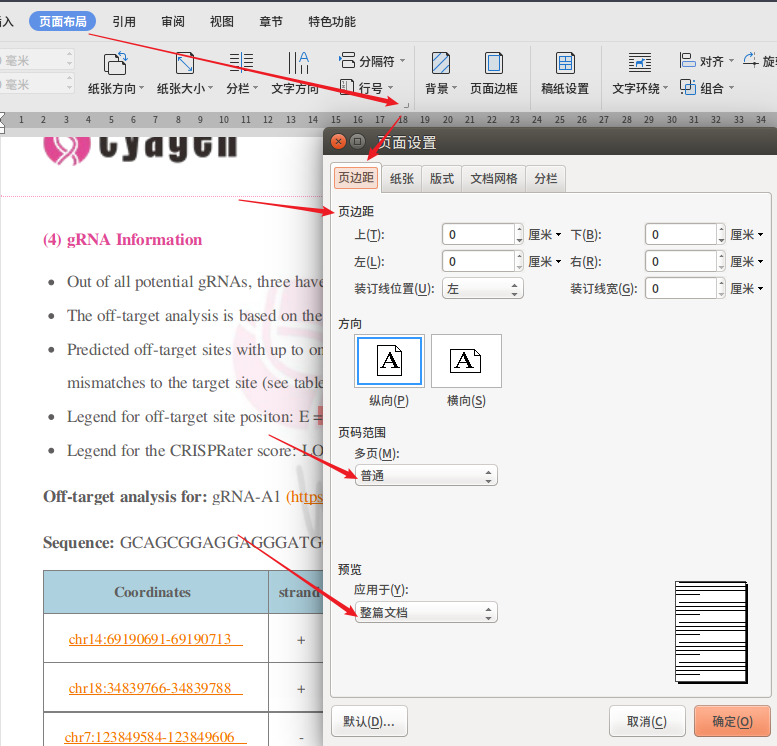
wps中页面偏移解决办法:
页面偏移主要是WPS默认页边距不为0导致的,而且由于转化的word中有分页符,所以需要在页面布局→页面设置→页边距→填入页边距值,选择应用于“整篇文档”即可。
参考:https://jingyan.baidu.com/article/2c8c281dea9bea4109252a54.html
LibreOffice Writer打开卡死解决办法:
暂无
尝试了下面的方法,但是还是卡
方式3:Office+win32com
该方式只适用于window系统,且有安装office。
1 | # 安装win32com(window外的系统会报错) |
问题1:报错AttributeError: 'NoneType' object has no attribute 'SaveAs2'
由于我这里安装的是WPS,所以wb对象其实是WPS的,没有这些操作。
参考:https://www.imooc.com/qadetail/325176
效果:
由于我没有安装Office,而且实际上我需要在服务器使用,所以就没有测试效果了。
方式4:GroupDocs Python SDK
注意:由于是上传到第三方,所以缺点是很明显的,对于敏感文件不宜轻易上传。
码字中…
还有一个类似的方式,效果也是不错,但是有限制,毕竟作者要恰饭,哈!
word→html
方式1:pydocx
1 | # # -*- coding: utf-8 -*- |
总结
对于pdf, word, html的互转,万精油的方法是LibreOffice和win32com,同时效果也是最好的,但是win32com注意只能适用于window系统。
对于html转PDF,推荐使用wkhtmltopdf,还可以使用puppeteer(未测试效果)。
2021.4.2更新,上面html转换后样式缺失的问题估计是不支持外链加载,可以使用juice(推荐)或者 html-packer插件处理。这两个插件都可以实现把html的外部资源合并到一个html中。
参考
Convert PDF to DOC (Python/Bash)
How to Convert PDF to Word With Python: A Step-by-Step Guide
本文链接: http://www.ionluo.cn/blog/posts/95230035.html
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
